前言
在之前的博客打造私有知识库中,我们通过向量数据库和大模型配合,实现了一个自己的知识库;今天我们使用langchain4j,在之前的基础上来试试RAG(Retrieval-Augmented Generation,检索增强生成),看看智能助手是怎么实现的。
我们先来看看RAG的核心原理:
1
2
3
| 检索(Retrieval):从外部知识库(如向量数据库、文档集合)中检索与用户查询相关的信息片段,通常使用向量相似度(如余弦相似度)或混合搜索(结合BM25、TF-IDF等)。
增强(Augmentation):将检索结果作为上下文输入,与大模型提示词(Prompt)结合,弥补LLM的知识局限性和幻觉问题。
生成(Generation):LLM基于增强后的上下文生成最终回答,确保内容与检索信息一致。
|
这也就是说我们在程序中实现了与大模型的对话功能之后,不满足于仅仅达到与直接使用大模型的网页端、客户端一样的普通对话效果,既然是自己开发程序,就希望能达到一些定制化的效果;这里可能有人又有疑问,既然大模型已经这么厉害了,那么我们自己还有什么可开发的,我们自己开发的功能还能比大厂更牛吗?其实不然,因为大模型是有一定限制的;
比如说,实时性限制,基本上每个模型的知识都不是实时的,都有一定延迟,如果我们想查询一下当天的天气,大模型本身就难以帮助我们;
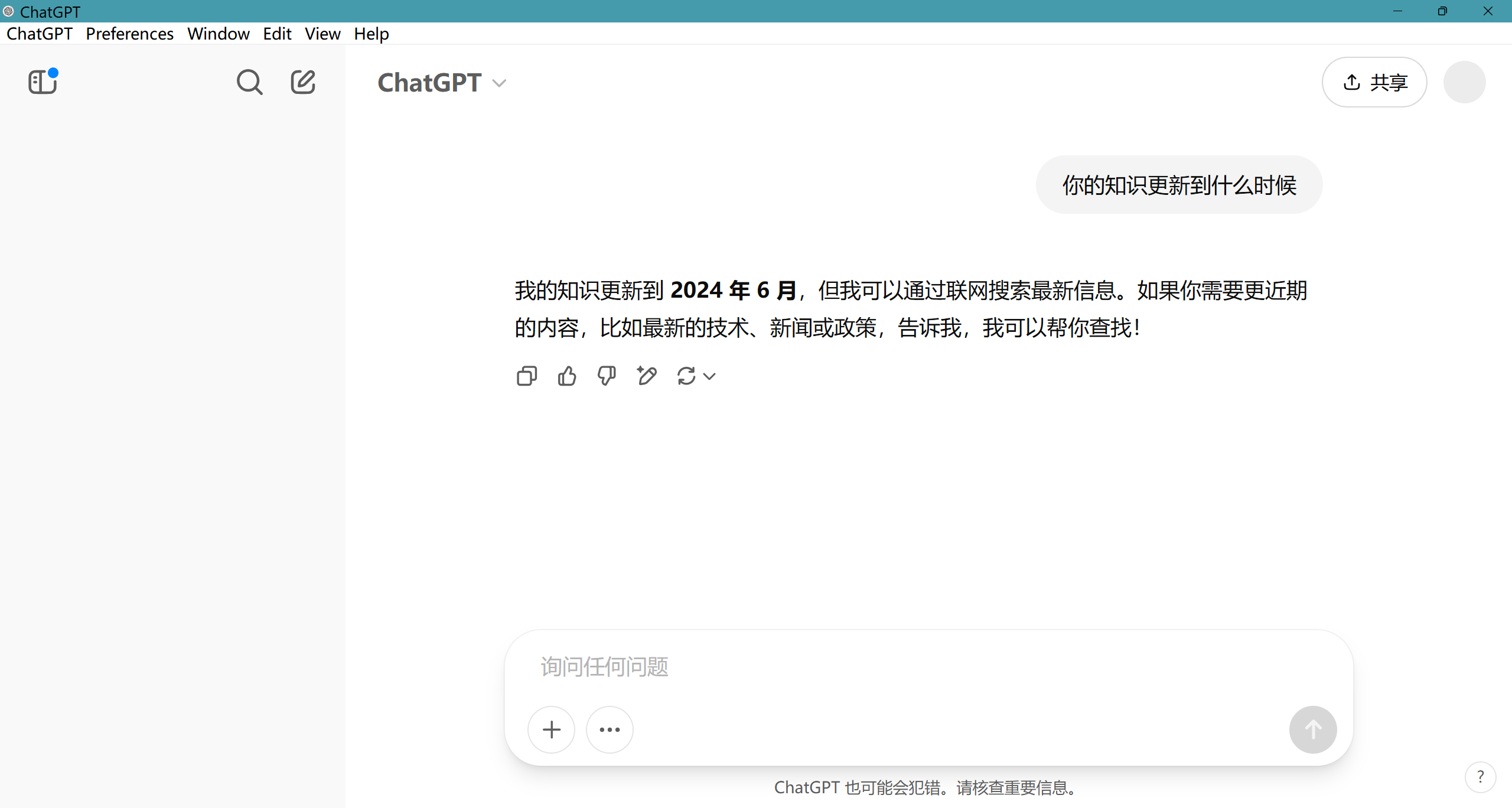
OpenAI的知识延迟
再比如,私密性限制,现在大模型只能搜集网络上的公开知识,一些私有数据大模型也是无法知晓的,而当我们问到相关知识的问题时,大模型当然也是无法回答的;例如一家票务公司,希望自家的人工智能能够与顾客互动,完成订票、退票等功能,而大模型并不知道该公司的票务数据,那大模型当然也就不能完成这些对话;
如果我们现在需要大模型能够回答一些定制类型的问题,或者进行一些定制类型的对话,我们应该如何做呢?别急,我们一步步来。
实现智能助手
对话应该是各种AI的基础功能了,我们之前在博客办公三件套接入OfficeAI助手中介绍过,AI服务既可以通过官方提供的客户端、网页端调用,也可以自己发送http请求调用,Langchain4j为我们提供了接口能方便的实现这一功能,同时提供了一些高级功能。
新建项目
新建一个项目LangChain4j-demo,JDK版本为21,SpringBoot版本为3.4.4,Langchain4j的版本为1.0.0-beta2
添加依赖
pom.xml文件中部分内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>${langchain4j-version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>${langchain4j-version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>${langchain4j-version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
</dependencies>
|
我们本次希望引入deepseek,但是依赖里没有deepseek,反而引入了openai,这是为什么呢?因为它们俩使用同一标准,所以我们可以使用openai的依赖调用deepseek
添加配置文件
新建application.properties文件,内容如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| spring.application.name=langchain4j-demo
server.port=8082
deepseek.api-key: sk-xxx
langchain4j.open-ai.chat-model.api-key=${deepseek.api-key}
langchain4j.open-ai.chat-model.model-name=deepseek-chat
langchain4j.open-ai.chat-model.log-requests=true
langchain4j.open-ai.chat-model.log-responses=true
langchain4j.open-ai.streaming-chat-model.api-key=${deepseek.api-key}
langchain4j.open-ai.streaming-chat-model.model-name=deepseek-chat
langchain4j.open-ai.streaming-chat-model.log-requests=true
langchain4j.open-ai.streaming-chat-model.log-responses=true
logging.level.dev.langchain4j=DEBUG
|
这里开启了’log-requests‘和’log-responses‘,配合’logging.level.dev.langchain4j=DEBUG‘,能打印出详细日志
调用DeepSeek实现对话
我们在Spring中构造实现对话的bean
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| @Configuration
public class DeepSeekChatModelConfig {
@Value("${deepseek.api-key}")
private String apiKey;
@Primary
@Bean
public OpenAiChatModel getDeepSeekChatModel() {
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey(apiKey)
.modelName("deepseek-chat")
.baseUrl("https://api.deepseek.com")
.temperature(0.4)
.maxTokens(2048)
.build();
return chatModel;
}
}
|
可以看到调用AI服务的三个资源分别是’baseUrl‘、’modelName‘、’apiKey‘,我们将其封装到对象中,将对象用注解’@Configuration‘、’@Bean‘的方式注入Spring,接下来我们就可以在项目中方便的使用它们;’@Primary‘是表示优先注入我们这里编写的bean,因为框架中默认使用OpenAI,已经注入了同样类型的bean;接下来我们直接在web接口中调用这个对象的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Resource
private OpenAiChatModel deepseekChatModel;
@GetMapping("/model")
public Result model(@RequestParam(value = "message", defaultValue = "Hello") String message) {
String response = deepseekChatModel.chat(message);
return Result.ok().message(response);
}
|
在postman中调用测试一下
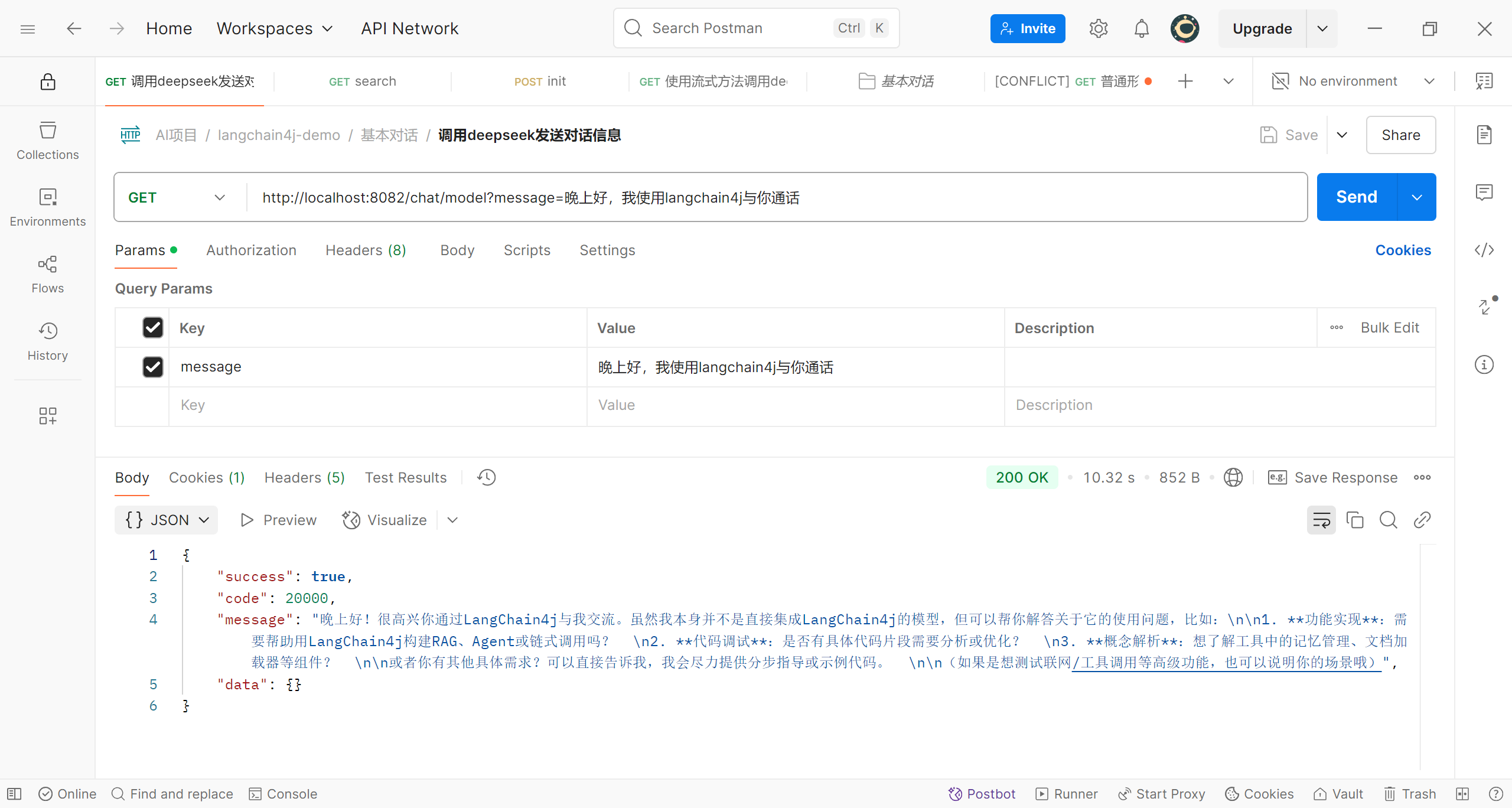
可以看到我们已经成功与deepseek对话了
实现流式回答
那么这就完美了吗?当然没有,你应该也感觉到了,这个请求执行的时间还是比较长的,根据上图,长达10s;而这还只是一个简单的回答,如果回答更长的话那么时间当然会更长,这样给用户的体验就会很差,那么我们要如何解决这个问题呢,答案就是使用流式回答;那么什么是流式回答?deepseek的解释是:“大模型的流式回答是一种实时生成和返回内容的技术,允许模型在计算过程中逐步输出结果,而非等待全部内容生成完毕后再一次性返回。”
要知道AI服务是按照token给我们输出答案的,LangChain4j框架中为我们提供了实现流式回答的接口,我们来看看如何实现;
首先我们必须引入依赖spring-boot-starter-webflux(详细看pom.xml文件),其次在刚才的类DeepSeekChatModelConfig中添加代码,将实现流式回答的bean注册到Spring
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
@Primary
@Bean
public OpenAiStreamingChatModel getOpenAiStreamingChatModel() {
OpenAiStreamingChatModel streamingChatModel = OpenAiStreamingChatModel.builder()
.apiKey(apiKey)
.modelName("deepseek-chat")
.baseUrl("https://api.deepseek.com")
.temperature(0.4)
.maxTokens(2048)
.build();
return streamingChatModel;
}
|
在接口中调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| @Resource
private OpenAiStreamingChatModel deepseekStreamingChatModel;
@GetMapping(value = "/streamModel", produces = "text/stream;charset=UTF-8")
public Flux<String> streamModel(@RequestParam(value = "message", defaultValue = "hello") String message) {
Flux<String> flux = Flux.create(sink -> {
deepseekStreamingChatModel.chat(message, new StreamingChatResponseHandler() {
@Override
public void onPartialResponse(String s) {
sink.next(s);
}
@Override
public void onCompleteResponse(ChatResponse chatResponse) {
sink.complete();
}
@Override
public void onError(Throwable throwable) {
sink.error(throwable);
}
});
});
return flux;
}
|
可以看到我们在注解’@GetMapping‘中设置接口响应类型和编码格式为’text/stream;charset=UTF-8‘;即以stream(流)的方式响应,编码为’UTF-8‘;返回的类型为’Flux‘,Flux为’langchain4j-reactor‘中的类,处理异步数据流相关的核心类,有三种信号:
- **
onNext**:推送一个元素。
- **
onComplete**:标记流正常结束。
- **
onError**:处理异常终止。
我们实现了接口StreamingChatResponseHandler,编写了这三种情况的处理方法;接下来我们测试一下
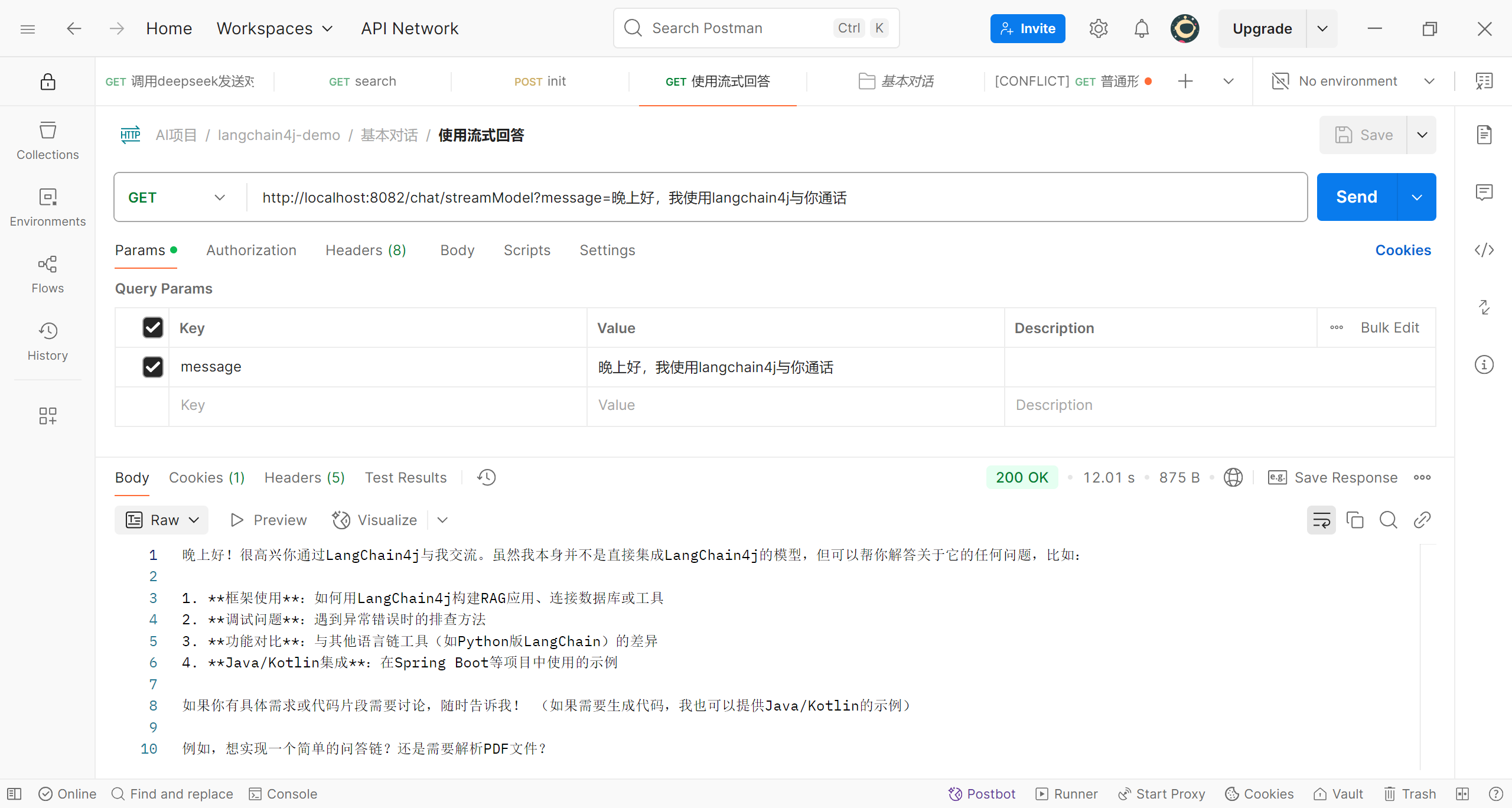
可以看到回答已经是逐步输出
实现记忆对话
我们已经实现了向deepseek发送问题,并接收她的回答,但是多问几个问题就会察觉到,现在还不能称之为’对话‘,因为deepseek并不能获取问题的上下文,所以现在的问题是孤立的;
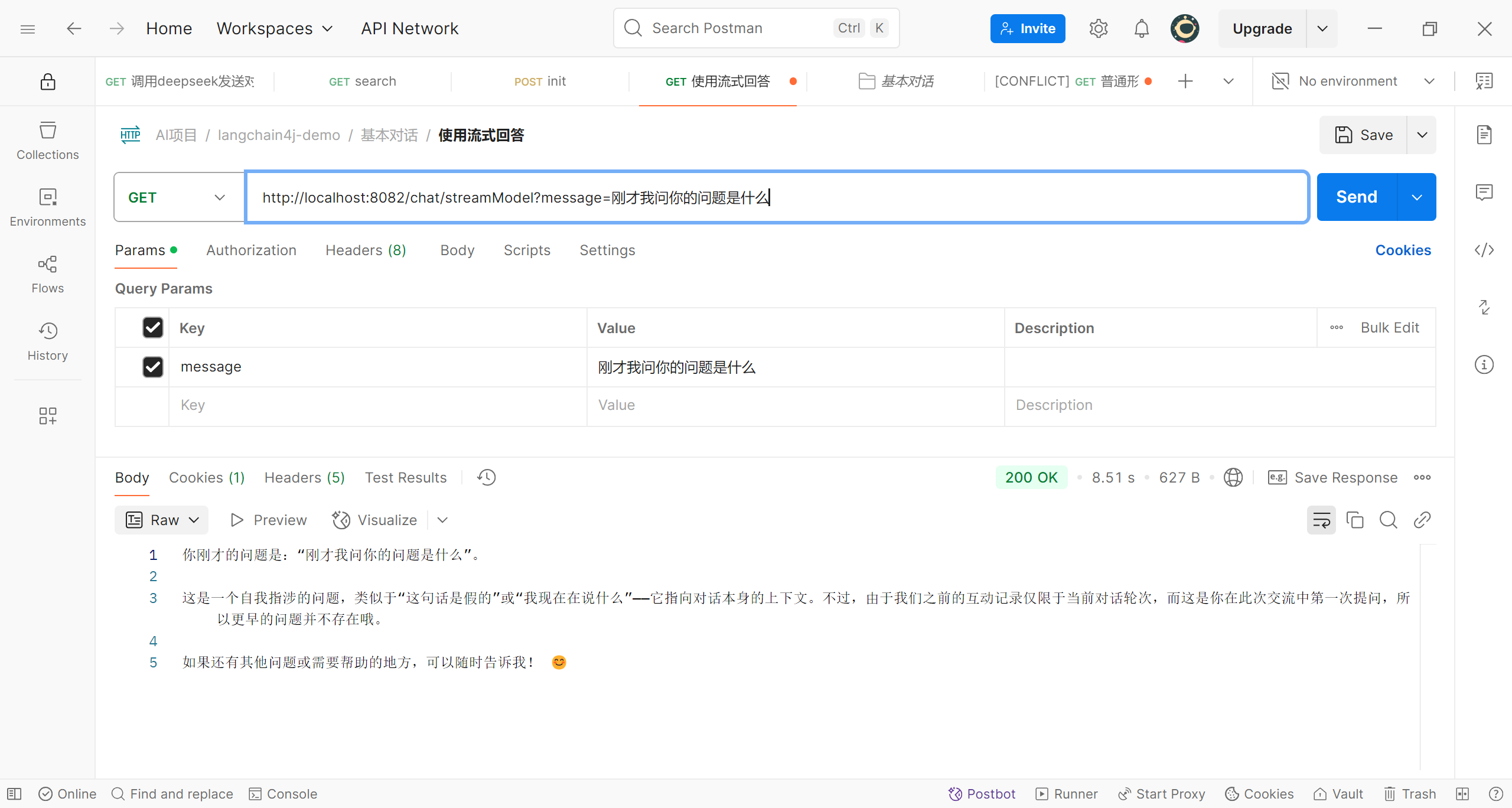
每次都是第一轮对话
这与我们在网页端或App上的情况可不相同,那么怎么才能让deepseek’记住‘我们对话的上下文呢?我们需要在第二次提问时将之前的问题和deepseek的回答都一起传送给deepseek,我们当然可以自己实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
@Test
public void MultipleRoundsChatTest() {
UserMessage userMessage1 = UserMessage.userMessage("你好,你是谁");
ChatResponse chatResponse1 = deepseekChatModel.chat(userMessage1);
AiMessage aiMessage1 = chatResponse1.aiMessage();
log.info(aiMessage1.text());
log.info("=============================================");
ChatResponse chatResponse2 = deepseekChatModel.chat(userMessage1, aiMessage1, UserMessage.userMessage(
"我第一次问的问题是什么"));
AiMessage aiMessage2 = chatResponse2.aiMessage();
log.info(aiMessage2.text());
}
|
但是当对话轮数多了之后也很麻烦,好在LangChain4j同样为我们准备了工具,我们来看看是怎么实现的;首先我们编写一个接口Assistant,接口中编写两个方法chat、chatByStream
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public interface Assistant {
String chat(String message);
TokenStream chatByStream(String message);
}
|
接下来我们在DeepSeekChatModelConfig中添加代码,将这个接口注册到Spring
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Bean
public Assistant getAssistant(OpenAiChatModel deepSeekChatModel,
OpenAiStreamingChatModel openAiStreamingChatModel) {
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(100);
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(deepSeekChatModel)
.streamingChatLanguageModel(openAiStreamingChatModel)
.chatMemory(chatMemory)
.build();
return assistant;
}
|
可以看到初始化了类MessageWindowChatMemory的对象,这个对象中初始化了存储对话信息的空间;接下来又用AiServices初始化了刚才我们新建的接口Assistant,并且传入了我们之前用于对话而注册的bean;我们现在就可以调用Assistant的对象来进行记忆对话;我们编写两个接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| @Slf4j
@RequestMapping("/memoryChat")
@RestController
public class MemoryChatController {
@Resource
private Assistant assistant;
@GetMapping("/model")
public String memoryChat(@RequestParam(value = "message", defaultValue = "hello") String message) {
String response = assistant.chat(message);
return response;
}
@GetMapping(value = "/streamModel", produces = "text/stream;charset=UTF-8")
public Flux<String> streamModel(@RequestParam(value = "message", defaultValue = "hello") String message) {
TokenStream tokenStream = assistant.chatByStream(message);
Flux<String> flux = Flux.create(fluxSink -> {
tokenStream
.onPartialResponse(s -> fluxSink.next(s))
.onCompleteResponse(chatResponse -> fluxSink.complete())
.onError(throwable -> log.error(throwable.getMessage(), throwable))
.start();
});
return flux;
}
}
|
接下来用postman测试
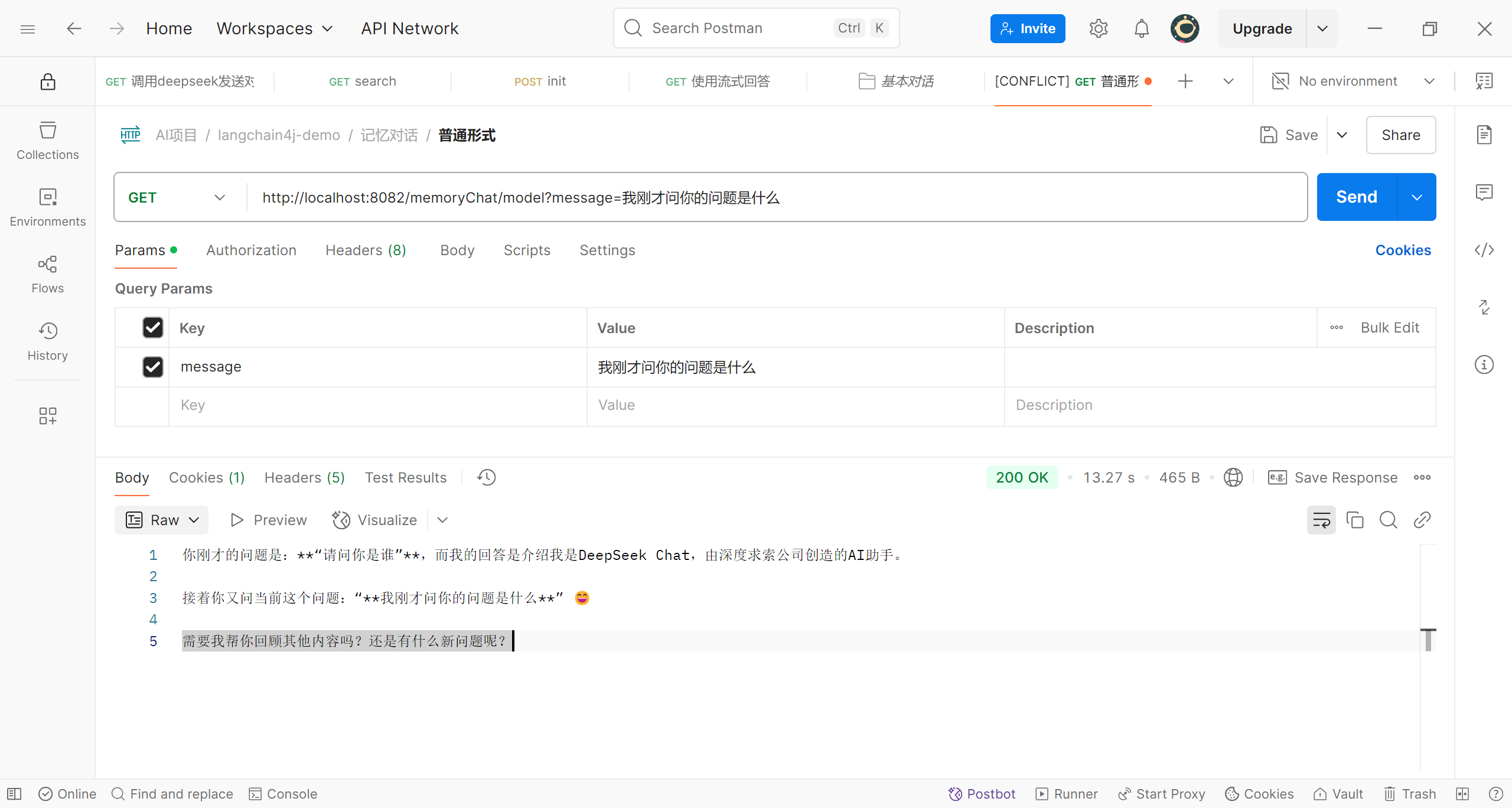
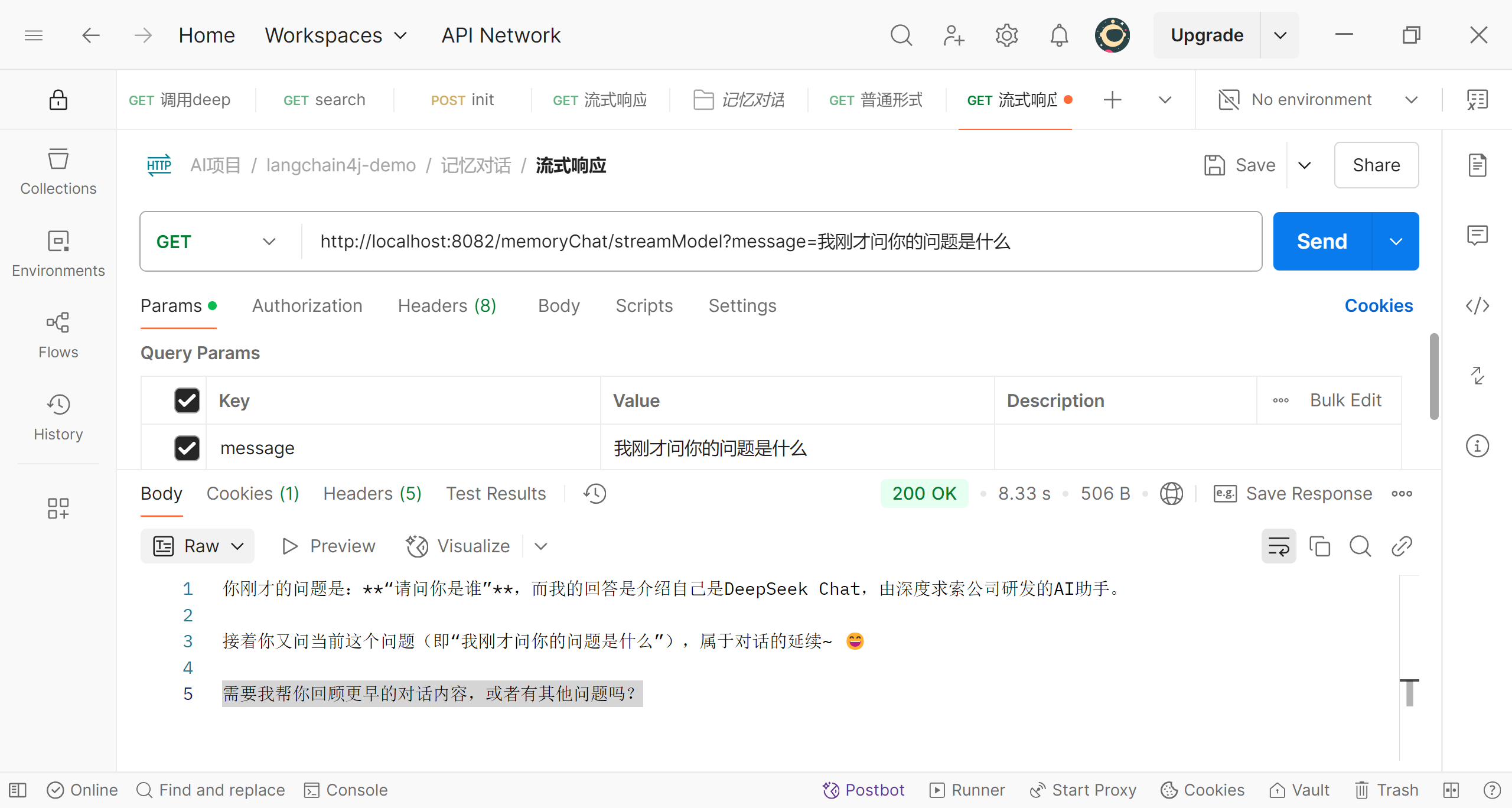
可以看到第二次提问时deepseek已经能够记住之前的提问;可能有人对这里看的不是很明白,稍微解释一下,AiServices.builder()不是直接创建接口Assistant的对象,而是创建了接口Assistant的一个动态代理对象,在代理对象中,就可以进行增强;增强的就是我们进行多轮对话测试的逻辑:将之前的提问和回答都记录下来并且在下次提问时将这些内容重新传给deepseek
实现对话隔离
我们现在已经可以和deepseek进行一场对话了,但是如果我们想同时进行两个或者多个对话呢?我们现在的程序是无法区分的,不过langchain4j也当然也帮我们考虑到了,我们只需要使用一个MemoryId;首先,为我的创建的接口Assistant中的两个方法添加参数memoryId,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public interface Assistant {
String chat(@MemoryId int memoryId, @UserMessage String message);
TokenStream chatByStream(@MemoryId int memoryId, @UserMessage String message);
}
|
接着,修改bean的注册代码
1
2
3
4
5
6
7
8
9
10
| @Bean
public Assistant getAssistant(OpenAiChatModel deepSeekChatModel,
OpenAiStreamingChatModel openAiStreamingChatModel) {
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(deepSeekChatModel)
.streamingChatLanguageModel(openAiStreamingChatModel)
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.builder().maxMessages(10).id(memoryId).build())
.build();
return assistant;
}
|
可以看到,这次我们不再使用统一的MessageWindowChatMemory对象来作为对话信息的存储空间,而是根据memoryId为每个对话创建独立的存储空间,以此来隔离对话信息(这里使用匿名对象的的方式构建chatMemoryProvider对象);我们选择从web页面传入chatId来作为对话的memoryId,修改web接口的代码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
@GetMapping("/model")
public String memoryChat(@RequestParam int chatId,
@RequestParam(value = "message", defaultValue = "hello") String message) {
String response = assistant.chat(chatId, message);
return response;
}
@GetMapping(value = "/streamModel", produces = "text/stream;charset=UTF-8")
public Flux<String> streamModel(@RequestParam int chatId,
@RequestParam(value = "message", defaultValue = "hello") String message) {
TokenStream tokenStream = assistant.chatByStream(chatId, message);
Flux<String> flux = Flux.create(fluxSink -> {
tokenStream
.onPartialResponse(s -> fluxSink.next(s))
.onCompleteResponse(chatResponse -> fluxSink.complete())
.onError(throwable -> log.error(throwable.getMessage(), throwable))
.start();
});
return flux;
}
|
可以说,我们的修改并不复杂,现在来做一下简单的测试
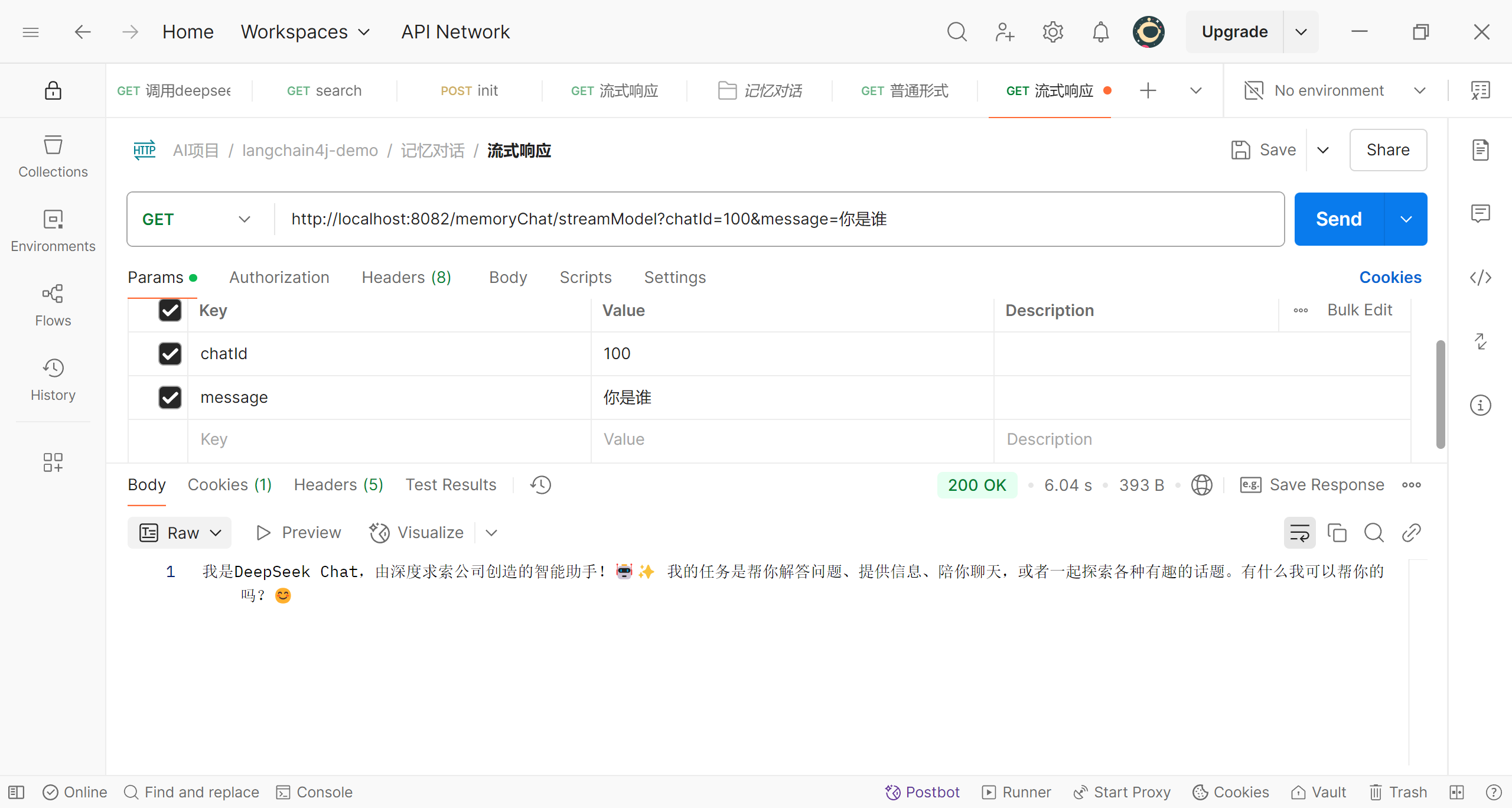
id为100的第一次提问
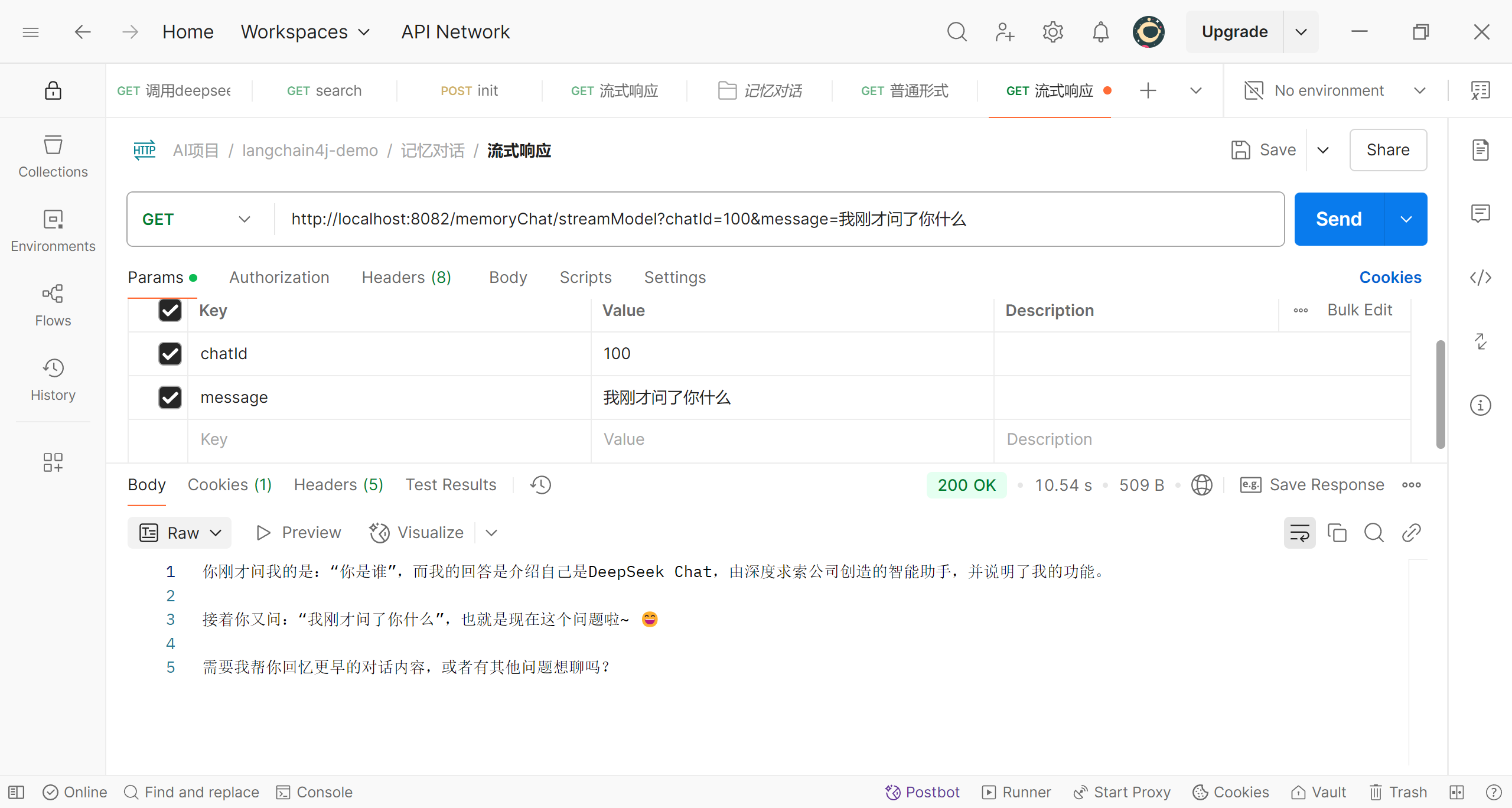
id为100的第二次提问
可以看到,我们使用同一个id时,deepseek知道我们之前提的问题
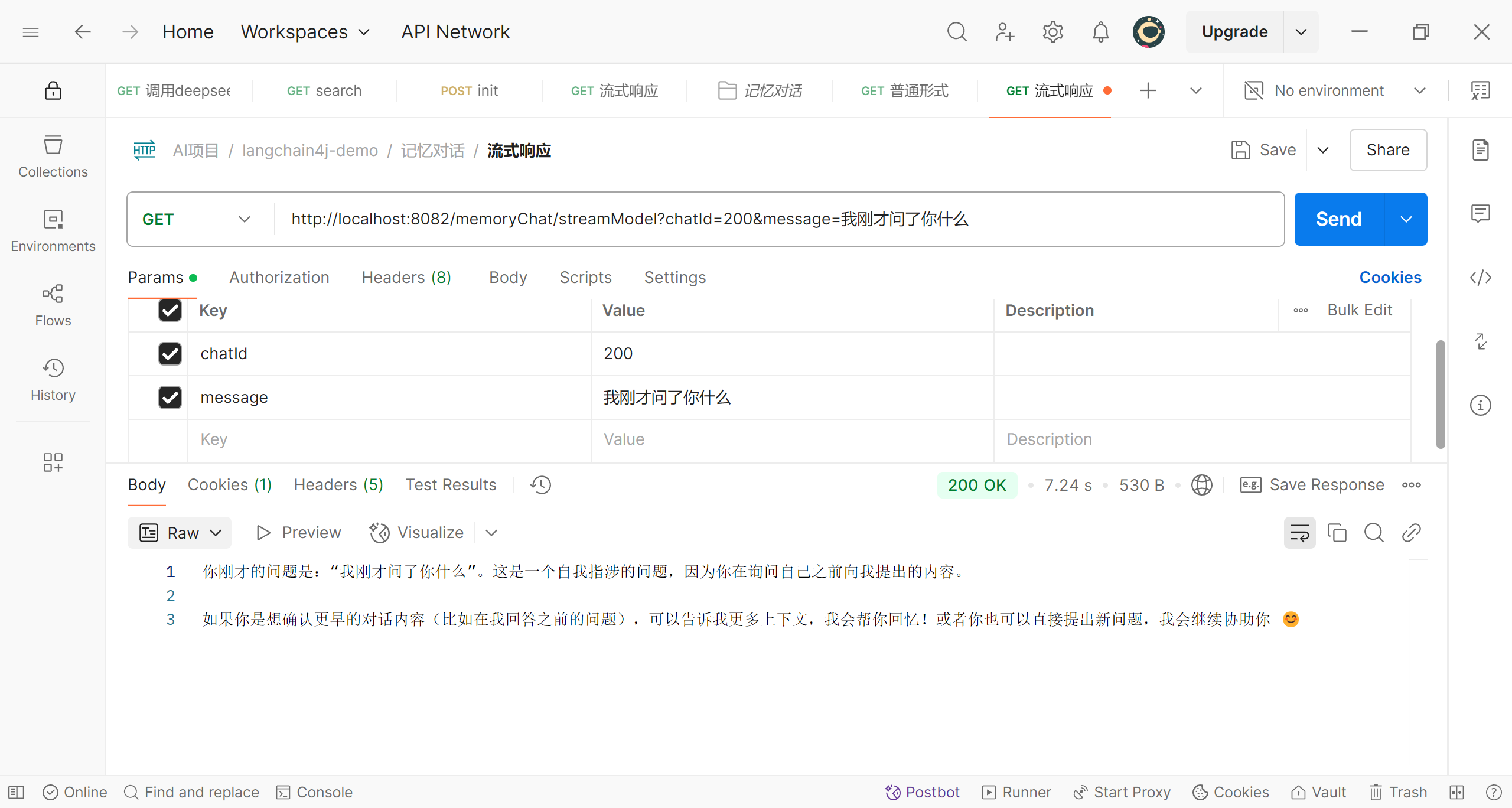
修改id后的提问
当我们修改了id,deepseek不再记得之前的问题,对于她来说,这是和我们的第一次对话;可见,根据id的不同,对话被隔离了
对话数据的持久化
我们现在已经让AI服务记住了我们的对话信息,那么这些对话信息现在存储在哪里呢?现在它们存储在内存中,但是很明显这是由缺陷的,首先内容的容量是有限的,如果使用的人太多或者进行多轮对话后会有内存溢出的风险;其次如果服务重启那么数据就丢失了;所以我们要对对话信息做持久化,也就是存储到数据库中。这次我们选择使用redis作为数据库,这是为了对话的性能考虑,实际项目中我们也可以存储到MySQL中或者两者同时使用(比如定时将redis中的数据同步到MySQL)。
我们首先创建一个数据持久化类PersistentChatMemoryStore,实现接口ChatMemoryStore,我们需要重写3个方法,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class PersistentChatMemoryStore implements ChatMemoryStore {
@Override
public List<ChatMessage> getMessages(Object memoryId) {
return List.of();
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
}
@Override
public void deleteMessages(Object memoryId) {
}
}
|
可以看到我们可以根据对话id将对话信息存储到数据库,并且对它进行增删改查;那么我们要在项目中引入redis,首先,还是引入依赖,在pom.xml文件中添加如下内容:
1
2
3
4
| <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
|
接着,在配置文件application.properties中添加redis的相关配置信息
1
2
| spring.data.redis.host=localhost
spring.data.redis.port=6379
|
我们编写一个RedisConfig类,在里面注册我们的StringRedisTemplate对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| @Configuration
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String redisHost;
@Value("${spring.data.redis.port}")
private int redisPort;
@Bean
public RedisConnectionFactory getRedisConnectionFactory() {
return new LettuceConnectionFactory(redisHost, redisPort);
}
@Bean
public StringRedisTemplate getStringRedisTemplate() {
StringRedisTemplate stringRedisTemplate = new StringRedisTemplate();
stringRedisTemplate.setConnectionFactory(getRedisConnectionFactory());
return stringRedisTemplate;
}
}
|
接着我们完善类PersistentChatMemoryStore,在3个方法中添加对应增删改查(我们将对话信息在redis中的过期时间设置为24小时),这里我们可以使用框架提供的ChatMessageDeserializer.messagesFromJson方法和ChatMessageSerializer.messagesToJson方法方便的将进行数据转换,使用@Component注解将其注册到SpringBoot
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| @Component
public class PersistentChatMemoryStore implements ChatMemoryStore {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
if (ObjectUtils.isEmpty(memoryId)) {
return List.of();
} else {
String value = stringRedisTemplate.opsForValue().get(memoryId.toString());
List<ChatMessage> chatMessages = ChatMessageDeserializer.messagesFromJson(value);
if (CollectionUtils.isEmpty(chatMessages)) {
return List.of();
} else {
return chatMessages;
}
}
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
if (!ObjectUtils.isEmpty(memoryId) && !CollectionUtils.isEmpty(list)) {
String messagesToJson = ChatMessageSerializer.messagesToJson(list);
stringRedisTemplate.opsForValue().set(memoryId.toString(), messagesToJson, 24, TimeUnit.HOURS);
}
}
@Override
public void deleteMessages(Object memoryId) {
if (!ObjectUtils.isEmpty(memoryId)) {
stringRedisTemplate.delete(memoryId.toString());
}
}
}
|
再修改我们之前编写的接口Assistant的注册方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
@Resource
private PersistentChatMemoryStore persistentChatMemoryStore;
@Bean
public Assistant getAssistant(OpenAiChatModel deepSeekChatModel,
OpenAiStreamingChatModel openAiStreamingChatModel) {
ChatMemoryProvider chatMemoryProvider = memoryId -> {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(persistentChatMemoryStore)
.build();
};
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(deepSeekChatModel)
.streamingChatLanguageModel(openAiStreamingChatModel)
.chatMemoryProvider(chatMemoryProvider)
.build();
return assistant;
}
|
首先我们将刚才注册的PersistentChatMemoryStore对象注入,并使用它构建类ChatMemoryProvider的对象;这样我们就将代码修改好了,接下来我们做一下测试,我们先发送一个问题
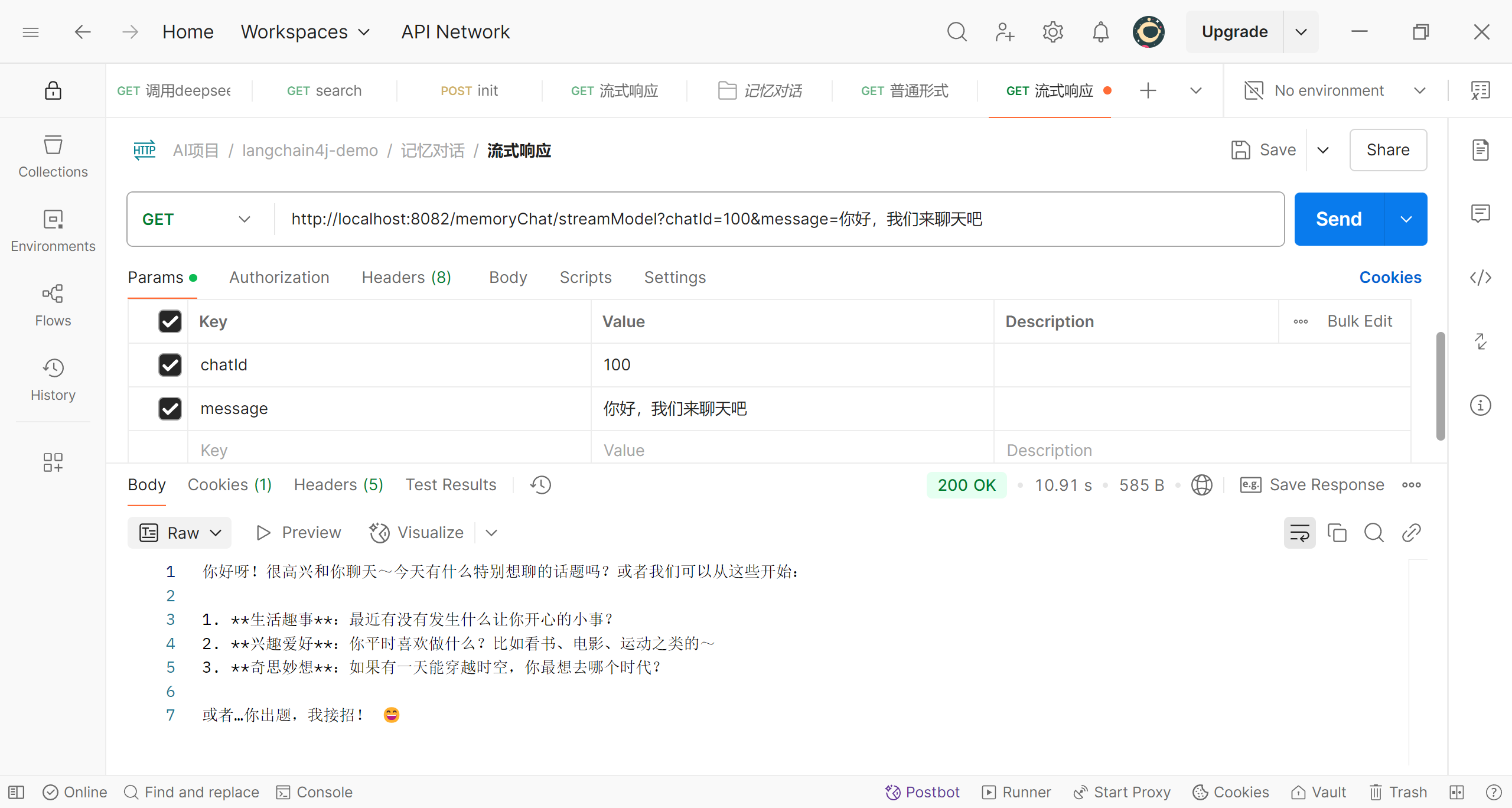
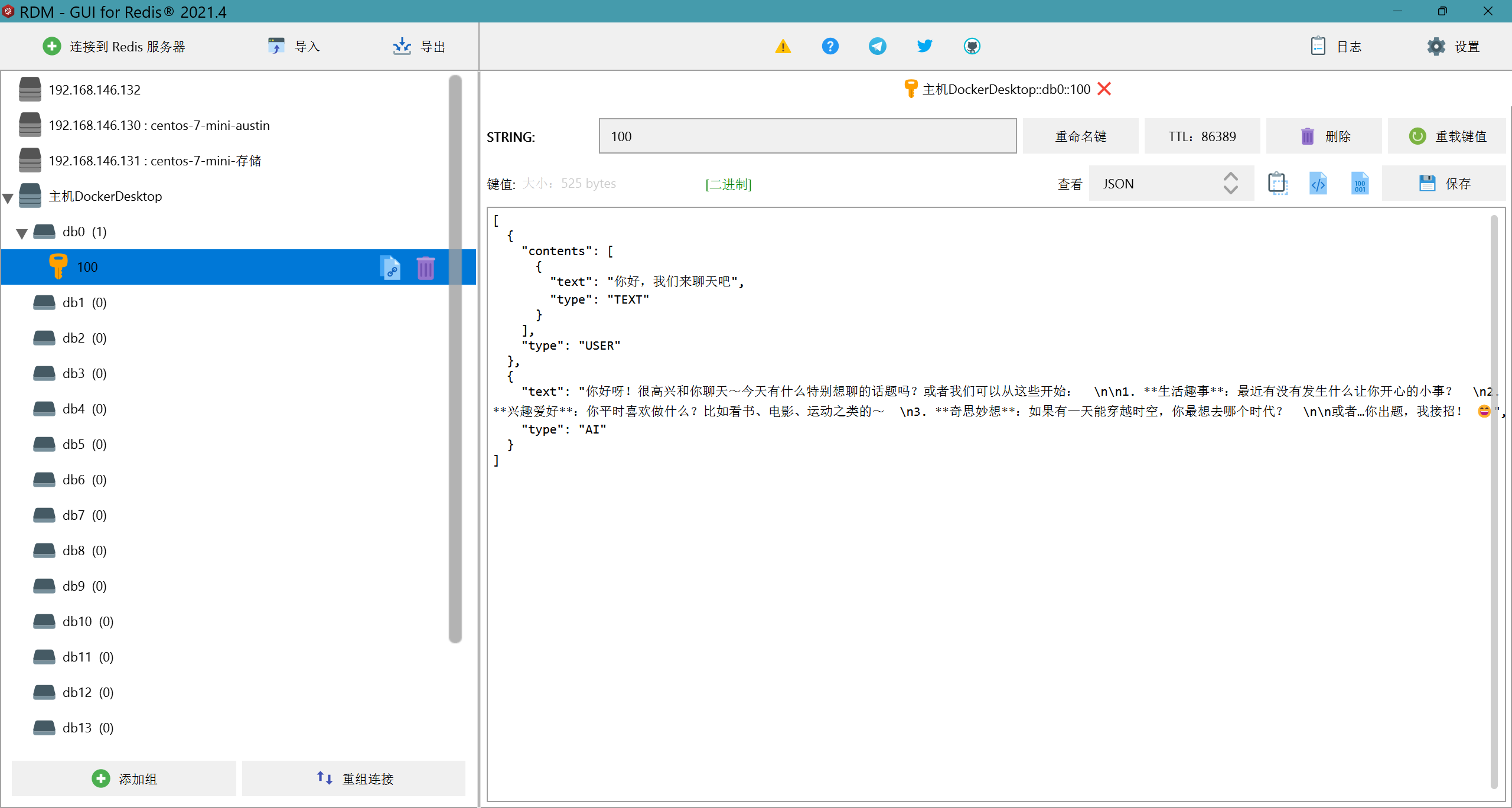
可以看到,我们提出的问题和deepseek的回答已经存储到了redis中,我们再继续提一个问题
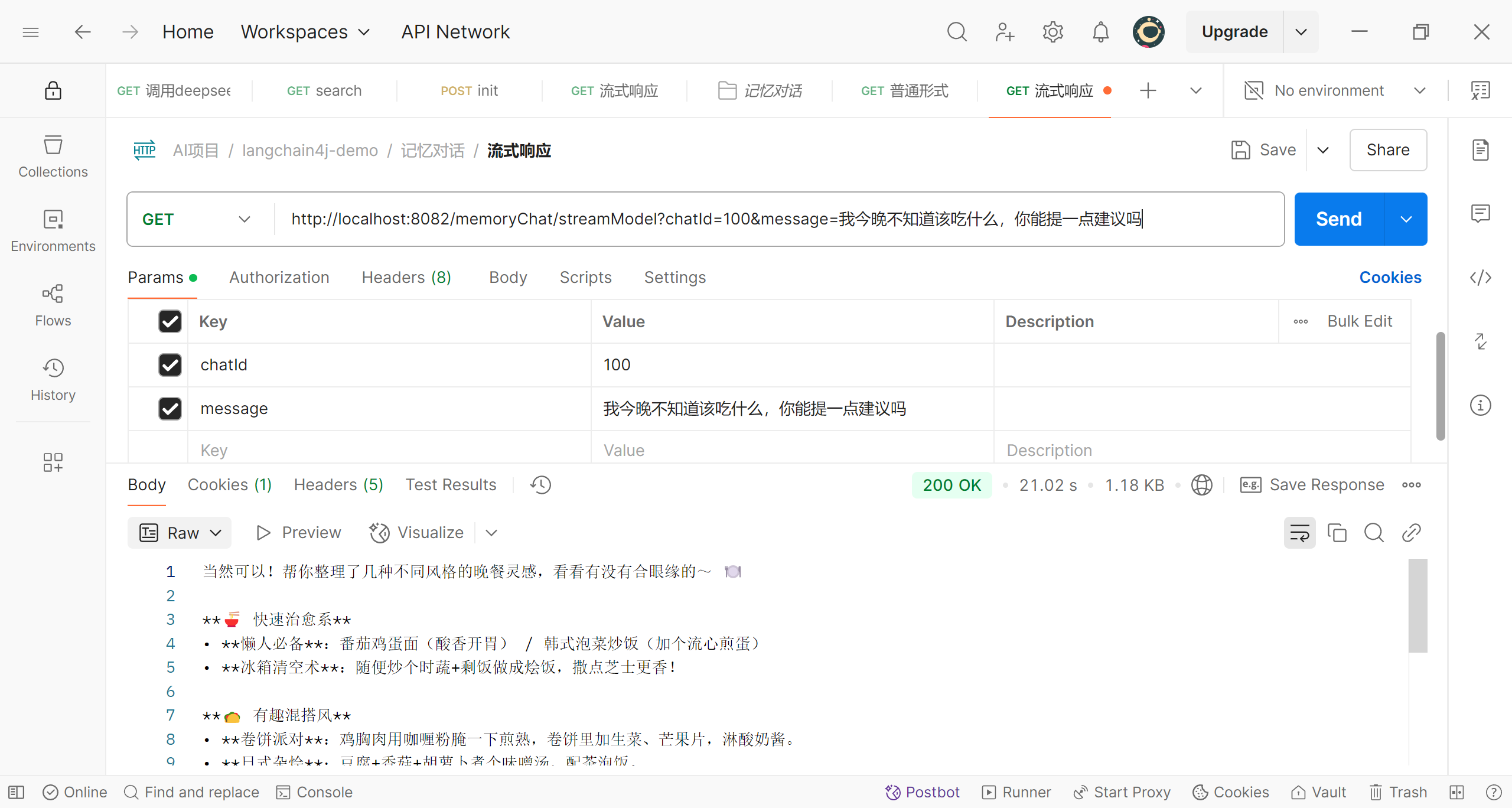
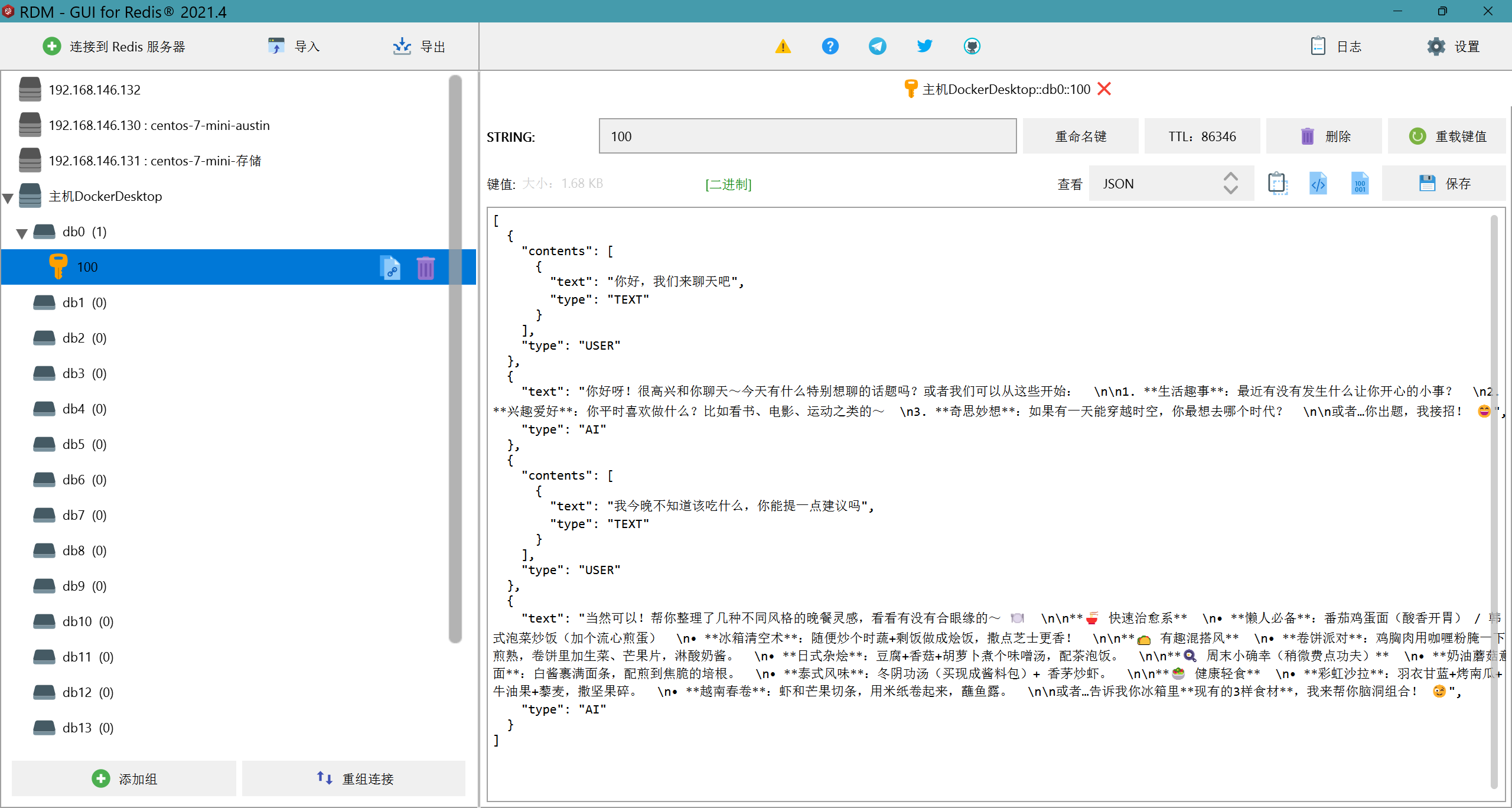
可以看到,我们的第二个问题也存储到了redis中;那么这样,我们对话数据的持久化就实现了
对话功能增强
天气查询助手
我们已经基本完成了对话的功能,现在到了关键一步,如果我们需要定制化的对话,那么我们需要告诉大模型什么样的对话需要被增强;例如:我们现在要查询某城市当天的天气,我们就需要让大模型在有关天气的对话时进行增强,那么是什么样的增强呢?就是提取出对话中有关城市等内容,调用第三方接口查询得到该城市的天气信息,再交给大模型对信息进行概括,生成最终回答;大致的流程图如下:
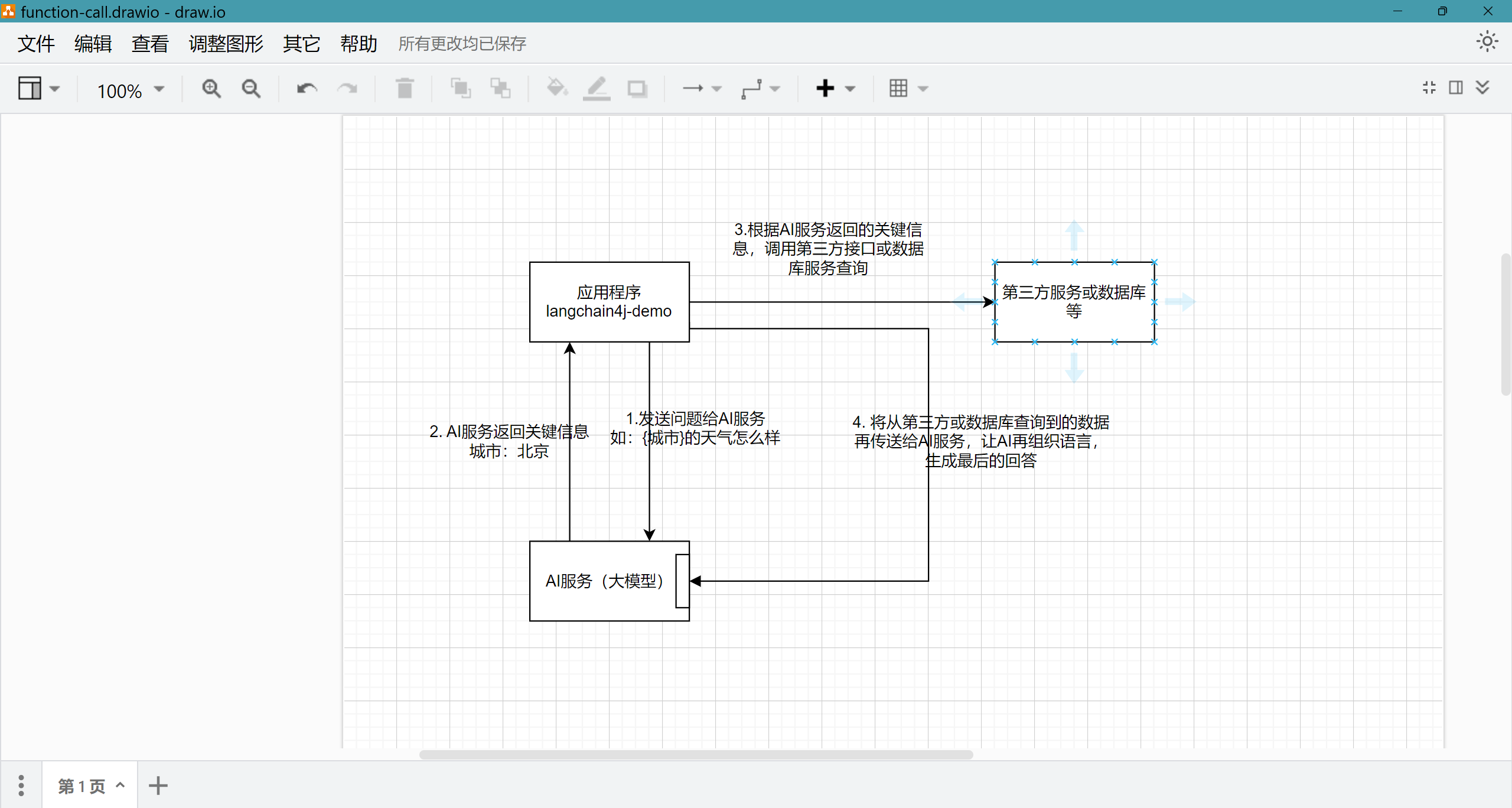
流程图
那么我们如何实现呢?langchain4j已经为我们提供了相应的工具,首先,我们创建一个天气的工具类
1
2
3
4
5
6
7
8
9
10
11
12
| @Slf4j
@Component
public class WeatherTool {
@Tool("获取指定城市的天气预报")
public String getWeather(@P("城市名称") String city) {
log.info("查询城市:{}", city);
String response = "北京 25℃ 晴天";
return response;
}
}
|
通过注解’ @Tool(“获取指定城市的天气预报”)‘我们告诉大模型这个工具类的作用及相关话题,通过注解’@P(“城市名称”)‘我们告诉大模型需要提取的参数;我们再注册一个接口Assistant的bean
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
@Bean
public Assistant weatherFunctionAssistant(OpenAiChatModel deepSeekChatModel,
OpenAiStreamingChatModel openAiStreamingChatModel,
WeatherTool weatherTool) {
ChatMemoryProvider chatMemoryProvider = memoryId -> {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(persistentChatMemoryStore)
.build();
};
Assistant weatherFunctionAssistant = AiServices.builder(Assistant.class)
.chatLanguageModel(deepSeekChatModel)
.streamingChatLanguageModel(openAiStreamingChatModel)
.chatMemoryProvider(chatMemoryProvider)
.tools(weatherTool)
.build();
return weatherFunctionAssistant;
}
|
使用AiServices.builder构建一个新的接口Assistant的对象,将weatherTool传入,使其绑定,然后我们就可以和之前一样调用这个对象进行对话了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| @Autowired
@Qualifier("weatherFunctionAssistant")
private Assistant weatherFunctionAssistant;
@GetMapping(value = "/getWeather", produces = "text/stream;charset=UTF-8")
public Flux<String> getWeather(@RequestParam int chatId,
@RequestParam(value = "message", defaultValue = "hello") String message) {
TokenStream tokenStream = weatherFunctionAssistant.chatByStream(chatId, message);
Flux<String> flux = Flux.create(fluxSink -> {
tokenStream
.onPartialResponse(s -> fluxSink.next(s))
.onCompleteResponse(chatResponse -> fluxSink.complete())
.onError(throwable -> log.error(throwable.getMessage(), throwable))
.start();
});
return flux;
}
|
现在我们来测试一下
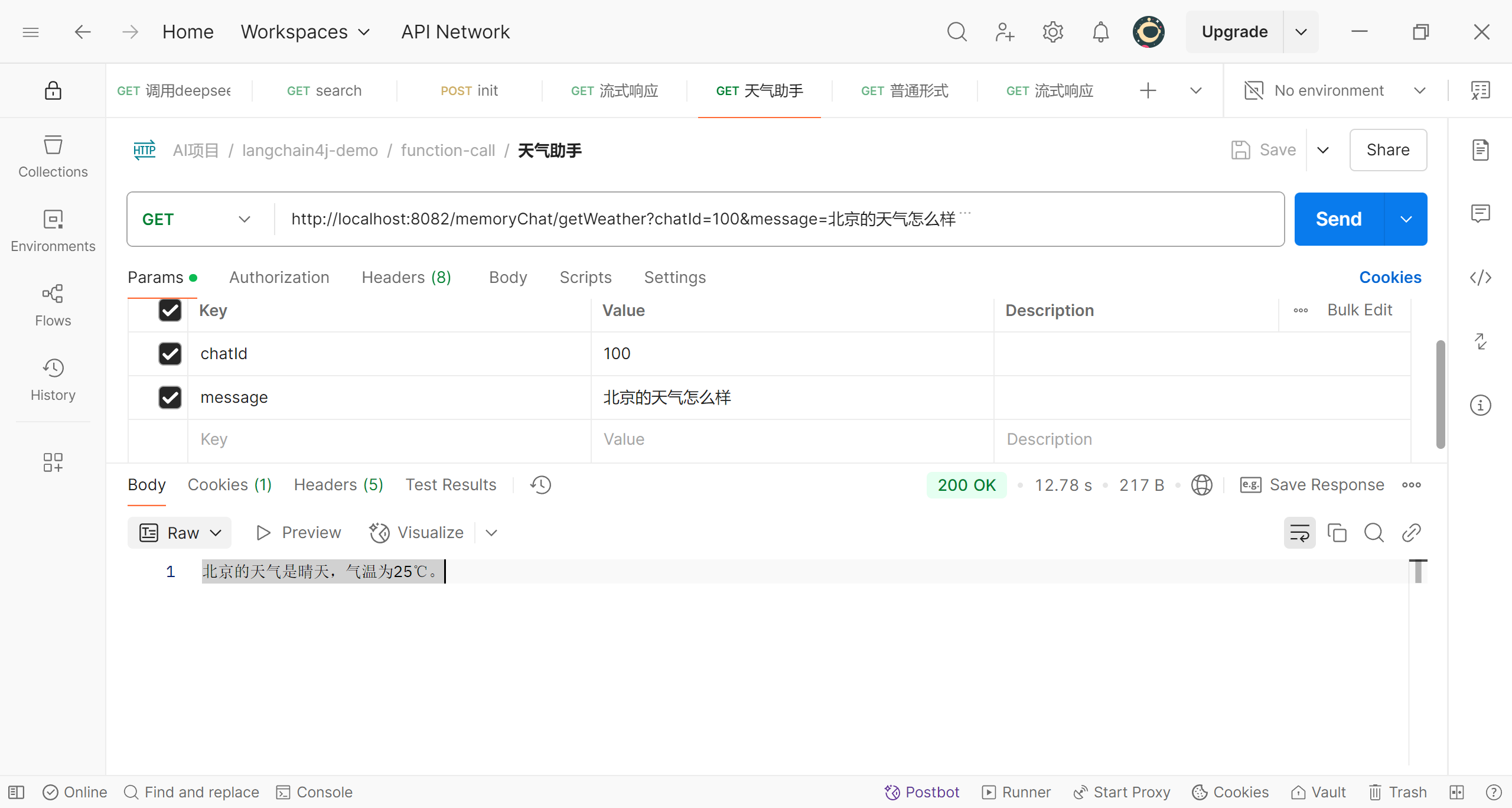
可以看到,现在我们询问有关天气的信息,大模型返回的是我们在工具类中提供的模拟查询的信息,而且并不是返回原始的信息,返回的是经过大模型加工后的信息;
票务助手
那么现在功能完善了吗,其实还没有,可能你注意到了,现在我们的程序在用户问到’相关‘问题时,可以做出反应,但是有时我们更希望程序能主动出击,就像客服人员一样,带着很强的目的性,引导用户进行相关对话,主动向用户’索要‘业务所需的数据;比如我们现在是一家票务公司,我们希望智能客服能引导顾客完成购票、退票等操作,那么我们的智能助手就需要向用户索要时间、车次、姓名等等数据,在客户提供了这些数据后,大模型会将这些关键信息提取出来返回给我们的应用程序,应用程序查询第三方接口或数据库并完成相关业务,再将结果返回给大模型,大模型生成语言结果后再返回给用户;大致流程图如下:
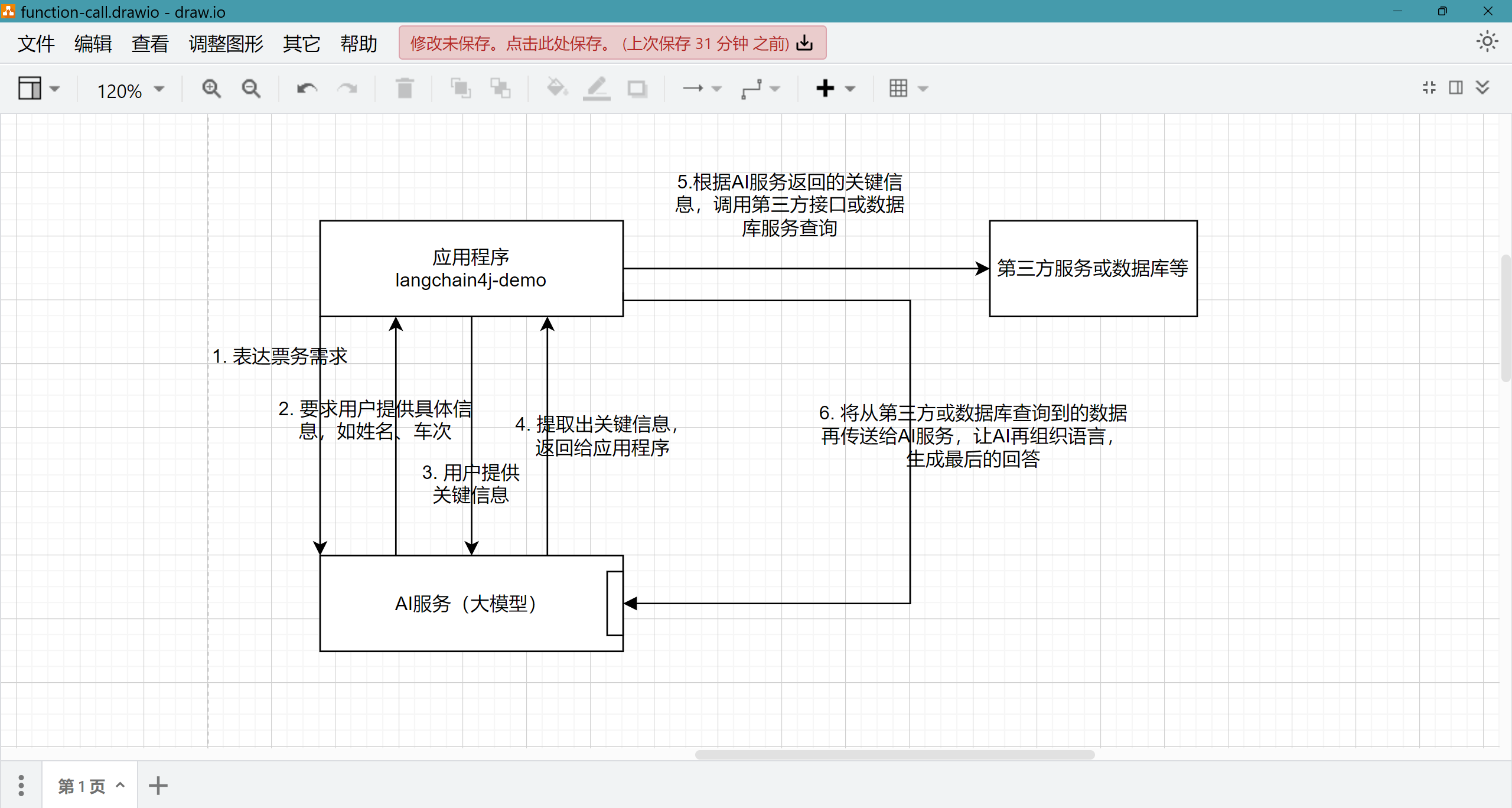
当然,langchain4j也为我们提供了相应的工具,这个工具就是@SystemMessage,deepseek对它的介绍:@SystemMessage 是 LangChain4j 框架中的一个注解,用于在 AI 对话系统 中定义系统级别的提示消息(System Prompt),通常用于向大语言模型(LLM)传递背景指令或角色设定。
1
2
| 定义系统提示词:通过 @SystemMessage 标注的方法或类,可以指定一组字符串作为系统消息,最终拼接后发送给 LLM。
动态变量填充:支持通过 @V 注解(或其他变量标记)在运行时替换消息中的占位符,生成最终的提示内容。
|
也就是说我们可以在该注解中添加关于其’角色‘和承担任务的设定;我们来看看它的源码
1
2
3
4
5
6
| @Target({TYPE, METHOD})
@Retention(RUNTIME)
public @interface SystemMessage {
String[] value();
String delimiter() default "\n";
}
|
其中:
- **
value()**:字符串数组,表示系统提示词的分段内容。
- **
delimiter**:拼接分段时的分隔符,默认为换行符 \n。
可以看到这个注解可以作用于类(接口、注解、枚举)或者方法上,我们这次就在方法上使用,在接口Assistant中添加一个方法
1
2
3
4
5
6
7
8
9
10
11
12
|
@SystemMessage("你是‘东兴’航空公司的票务助理。请以友好、乐于助人的方式来与用户互动。你正在通过在线聊天系统与用户互动。" +
"在提供车票信息之前,你必须始终从用户处获取以下信息:车次、客户姓名。" +
"今天的日期是{{current_date}}")
TokenStream chatForTicket(@MemoryId int memoryId, @UserMessage String message, @V("current_date") String date);
|
基本配置和前面一样,但是使用@SystemMessage设定了该方法(也可以单独使用一个接口)的角色和任务,我们使用{{current_date}}传入了一个参数,这些扩展参数都是业务需要的,用注解’@V‘来标明;和天气查询助手一样,我们继续编写一个Tool(工具),并将其注册到Spring
1
2
3
4
5
6
7
8
9
10
11
12
| @Slf4j
@Component
public class TicketTool {
@Tool("车票信息查询")
public String getTicketInfo(@P("车次") String trainNo, @P("客户姓名") String name) {
log.info("车次:{}, 客户姓名:{}", trainNo, name);
String response = "下午2时15分发车,在3站台检票";
return response;
}
}
|
接下来我们再实例化一个接口Assistant的对象,在其中传入我们刚刚创建的Tool
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
@Bean
public Assistant ticketFunctionAssistant(OpenAiChatModel deepSeekChatModel,
OpenAiStreamingChatModel openAiStreamingChatModel,
TicketTool ticketTool) {
ChatMemoryProvider chatMemoryProvider = memoryId -> {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(persistentChatMemoryStore)
.build();
};
Assistant ticketFouctionAssistant = AiServices.builder(Assistant.class)
.chatLanguageModel(deepSeekChatModel)
.streamingChatLanguageModel(openAiStreamingChatModel)
.chatMemoryProvider(chatMemoryProvider)
.tools(ticketTool)
.build();
return ticketFouctionAssistant;
}
|
接下来我们就可以在web接口中使用刚才实例化的对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
@Autowired
@Qualifier("ticketFunctionAssistant")
private Assistant ticketFunctionAssistant;
@GetMapping(value = "/getTicketInfo", produces = "text/stream;charset=UTF-8")
public Flux<String> getTicketInfo(@RequestParam int chatId,
@RequestParam(value = "message", defaultValue = "hello") String message) {
TokenStream tokenStream = ticketFunctionAssistant.chatForTicket(chatId, message, LocalDate.now().toString());
Flux<String> flux = Flux.create(fluxSink -> {
tokenStream
.onPartialResponse(s -> fluxSink.next(s))
.onCompleteResponse(chatResponse -> fluxSink.complete())
.onError(throwable -> log.error(throwable.getMessage(), throwable))
.start();
});
return flux;
}
|
我们来测试一下
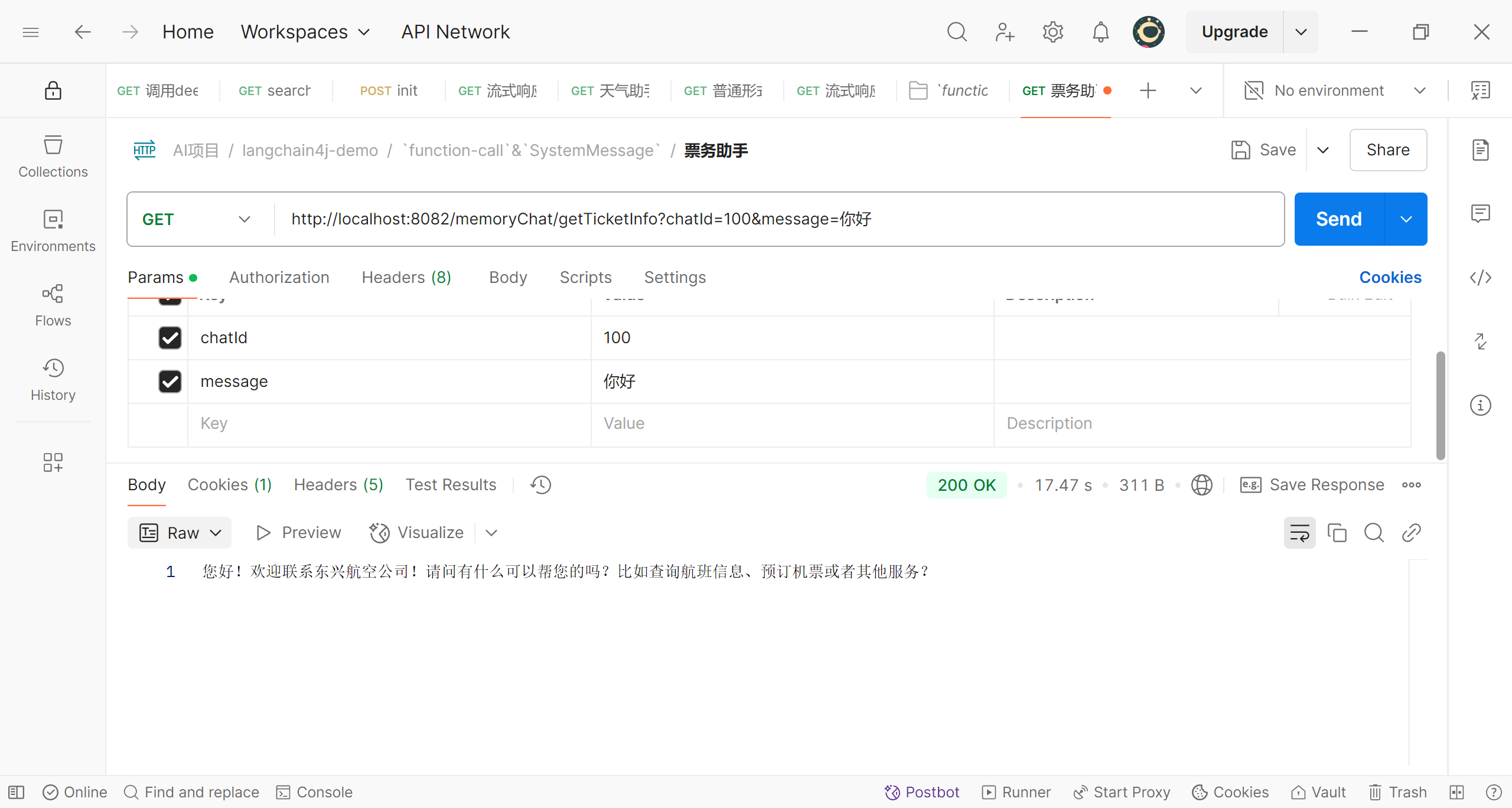
可以看到,我们向之前那样打招呼,而这次程序直接表明了自己的身份,并引导我们进行业务相关的对话
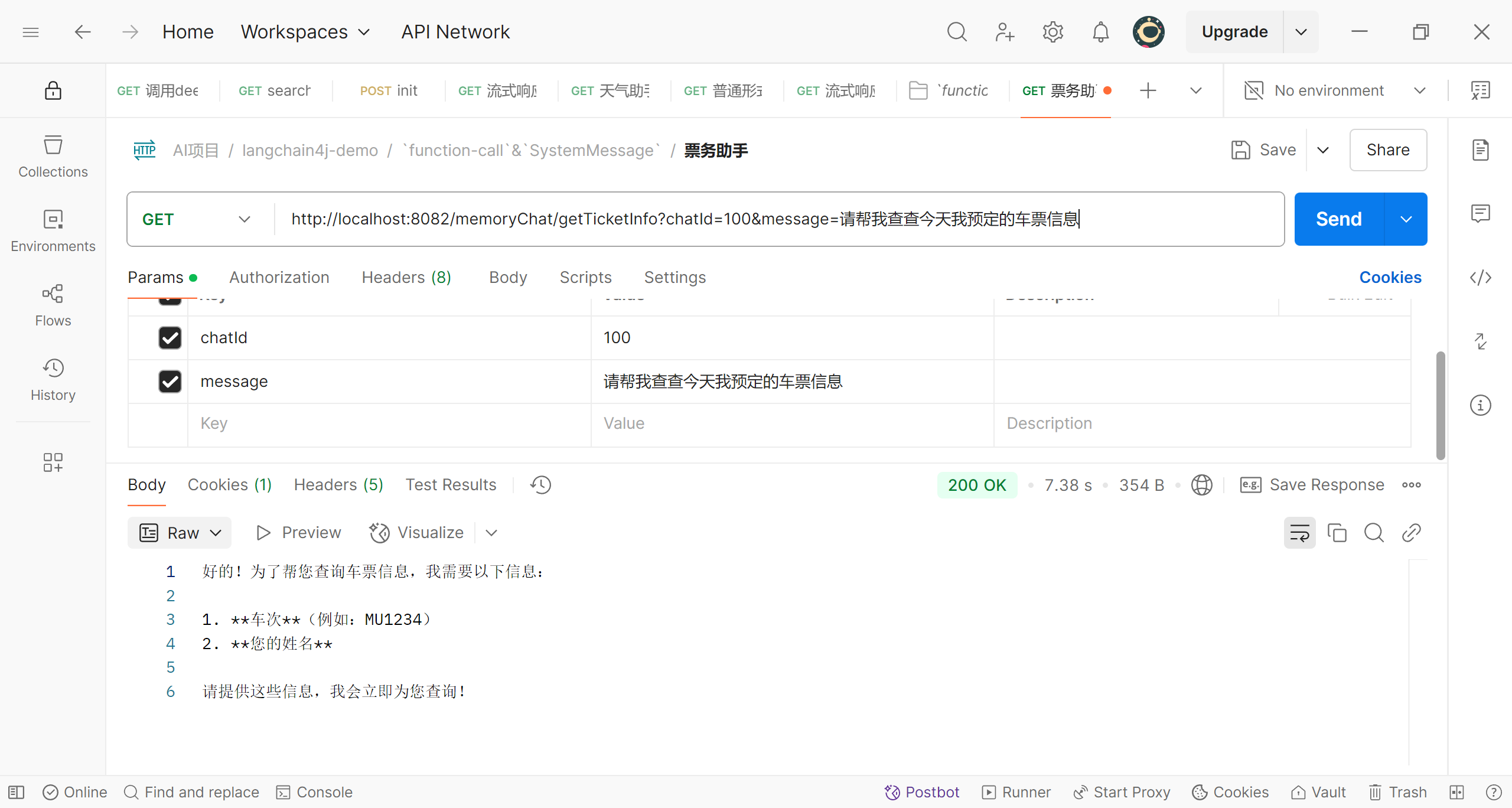
我们提出了要求,程序则提示我们输入需要输入相关信息
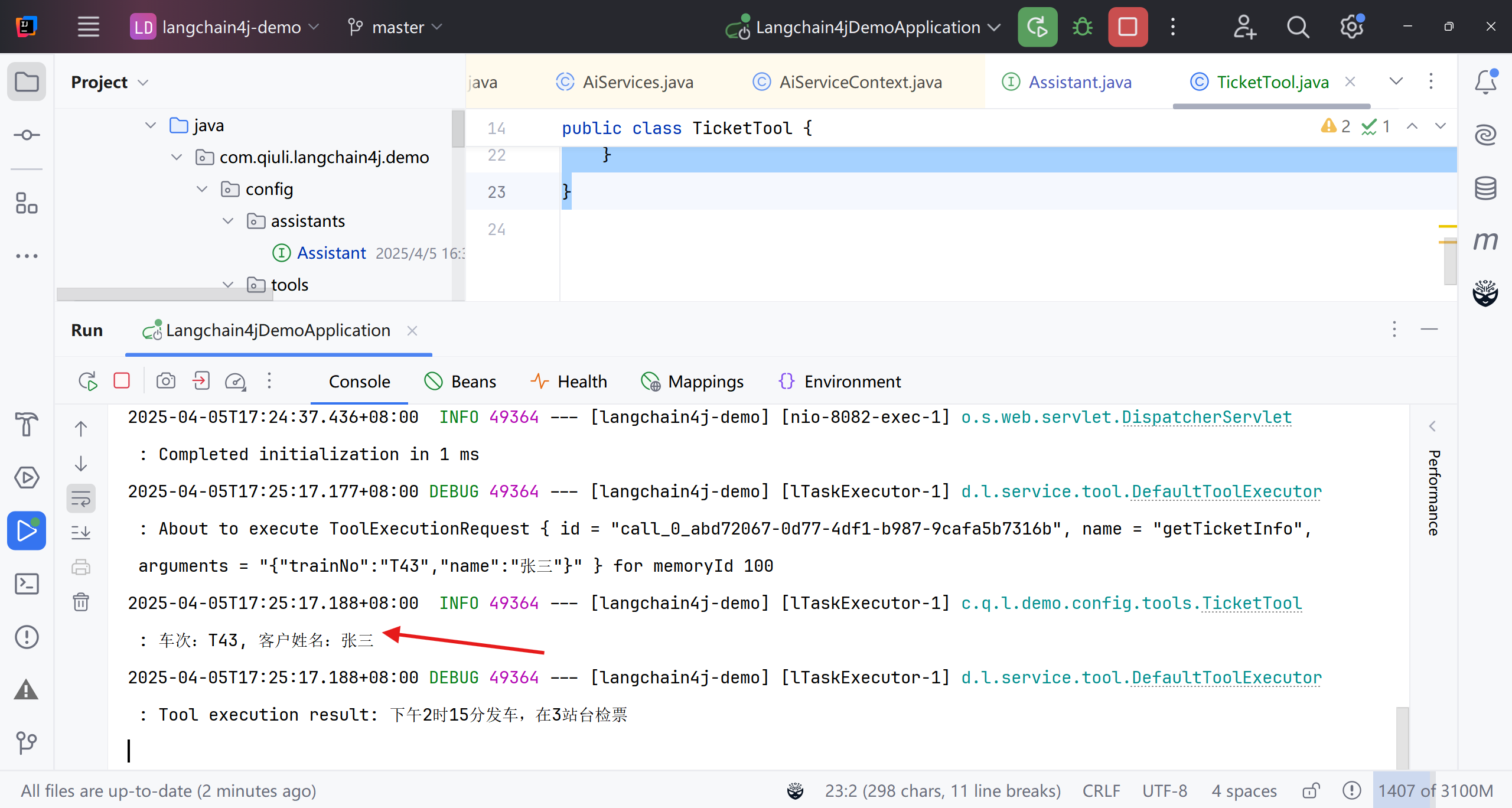
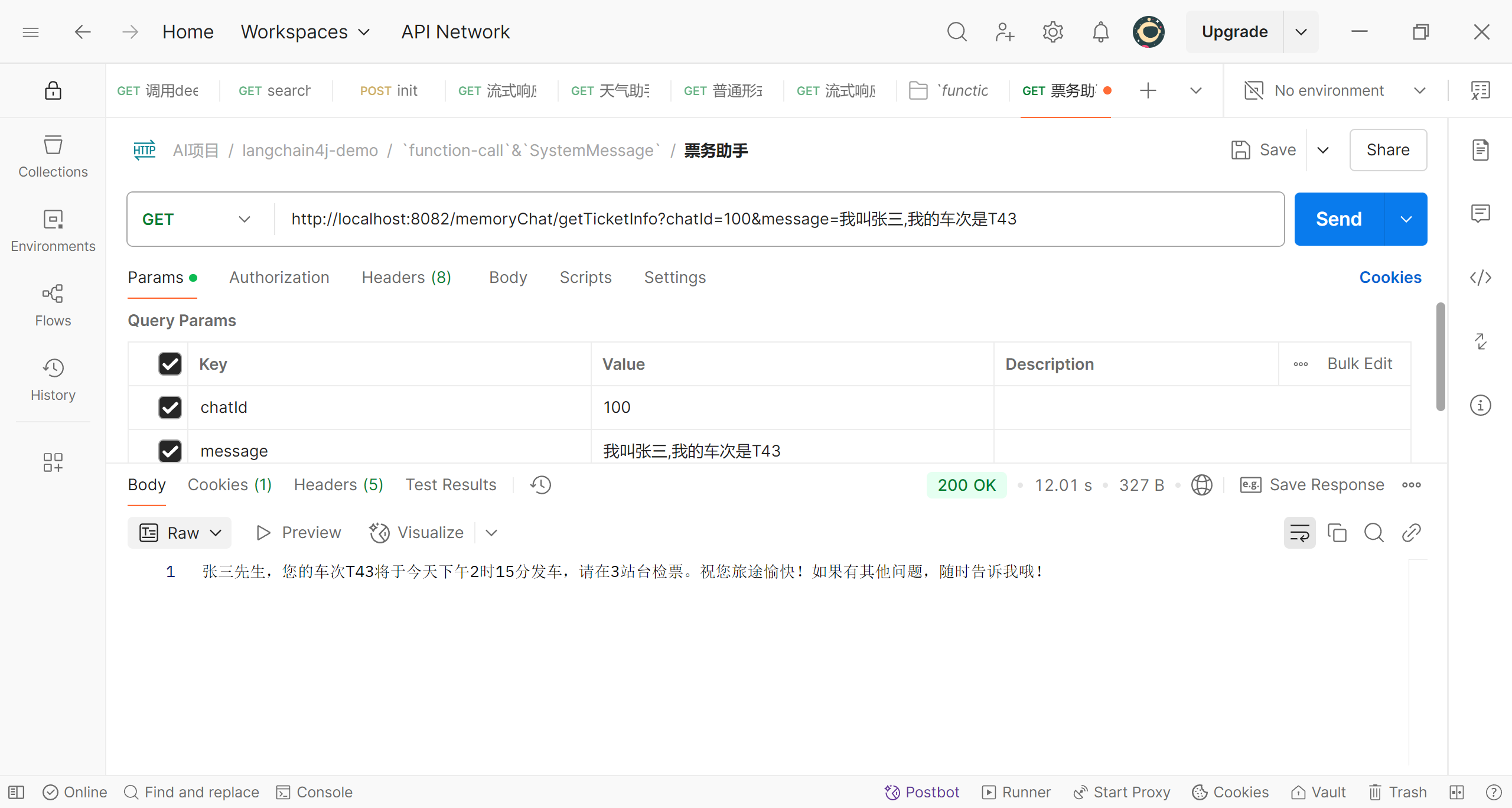
我们提供了相关信息,大模型将我们提供的关键信息提取出来,我们用这些信息处理了业务后,将处理结果传递给大模型,接着大模型将这些结果加工后,生成了最后的语意结果返回给了用户
使用RAG实现私有知识库
在博客打造私有知识库中,我们打造的私有知识库可以高效的使用相似性检索,为我们在个人或组织数据库中查找内容;但是有一个缺点是返回的数据是没有经过大模型处理的原始数据,这就给人一种‘卡壳’的感觉,我们明明用自然语言进行提问,得到的回复却是冰冷的数据;那如果我们希望程序也能够向智能助手一样,用自然语言进行回复呢?这就是我们要介绍的RAG(Retrieval-Augmented Generation,检索增强生成)。简单说,RAG的实现流程与之前的私有知识库是一样的,分为两个部分;首先要读取收集好的数据,通过向量模型将其转化为向量,存储到向量数据库;查询时,也是先将客户的问题交给向量模型转化为向量,再根据该向量在向量数据库中查询;比之前多一个步骤的是,将查询出的结果再发送给大模型进行语言加工,这样就能返回自然语言的查询结果了。
项目效果
我们先来看看项目的效果
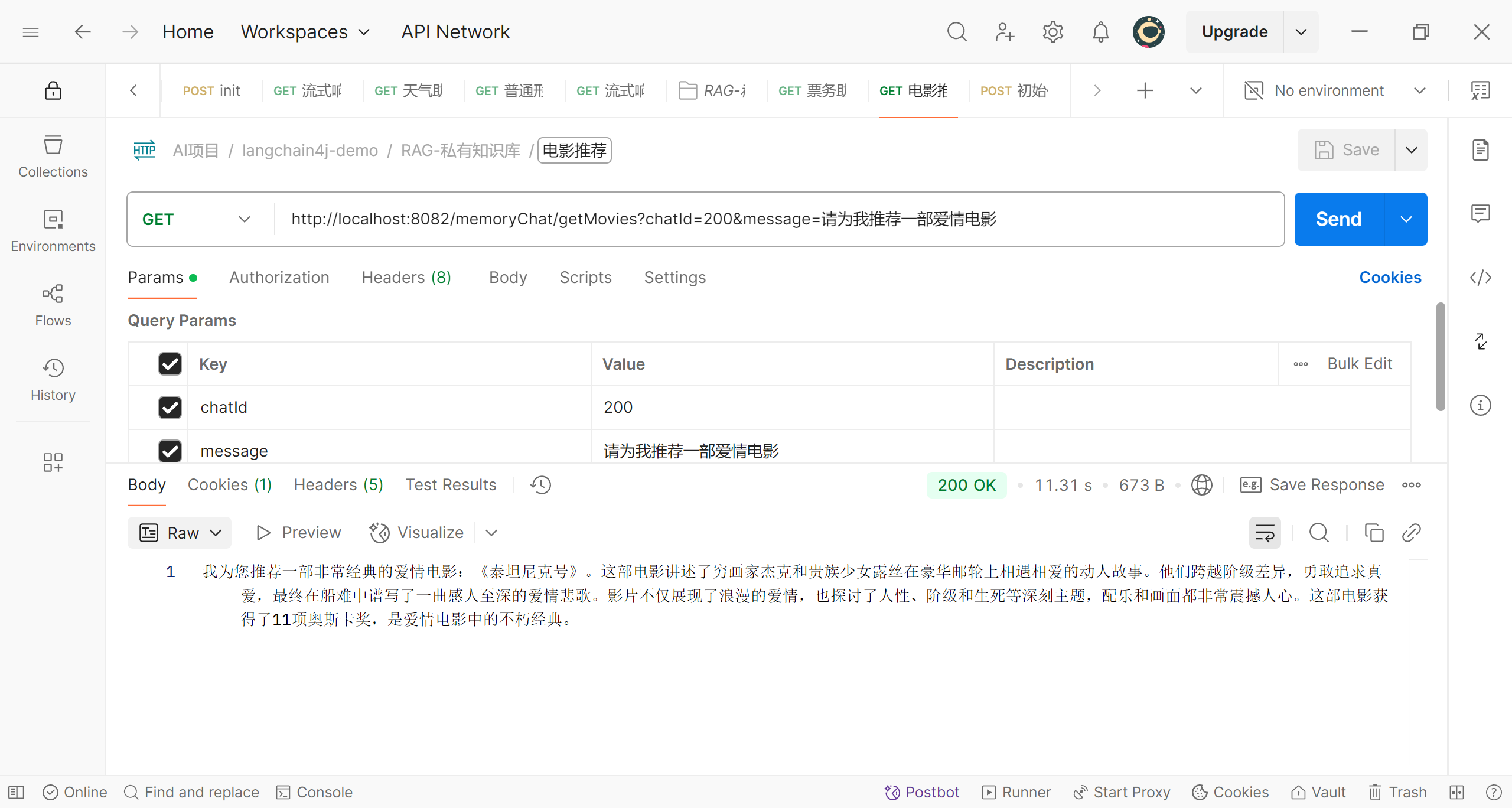
可以看到,现在当我们向程序提问,程序不仅仅给出推荐的电影,而且使用自然语言回答,真正实现了问答效果。
实现
那么我们来看看如何实现,我们依然使用阿里云百炼的通用文本态向量和向量数据库Milvus,关于这两者的安装和使用可以查看博客SpringAI打造私有知识库。
后端代码实现
将向量数据库的bean注册到Spring
添加依赖
在pom.xml文件中添加如下依赖:
1
2
3
4
5
| <dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-milvus</artifactId>
<version>${langchain4j.version}</version>
</dependency>
|
添加配置
在application.properties中添加需要的配置项(向量数据库Milvus的安装可以查看文章打造私有知识库)
1
2
3
4
5
6
7
8
9
| langchain4j-demo.movies.file-path=classpath:movies/movies.csv
langchain4j-demo.milvus.host=localhost
langchain4j-demo.milvus.port=19530
langchain4j-demo.milvus.databaseName=default
langchain4j-demo.milvus.collectionName=movies
langchain4j-demo.milvus.idFieldName=doc_id
langchain4j-demo.milvus.textFieldName=content
langchain4j-demo.milvus.metadataFieldName=metadata
langchain4j-demo.milvus.vectorFieldName=embedding
|
添加代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| @Configuration
public class EmbeddingStoreConfig {
@Value("${langchain4j-demo.milvus.host}")
private String host;
@Value("${langchain4j-demo.milvus.port}")
private int port;
@Value("${langchain4j-demo.milvus.databaseName}")
private String databaseName;
@Value("${langchain4j-demo.milvus.collectionName}")
private String collectionName;
@Value("${langchain4j-demo.milvus.idFieldName}")
private String idFieldName;
@Value("${langchain4j-demo.milvus.textFieldName}")
private String textFieldName;
@Value("${langchain4j-demo.milvus.metadataFieldName}")
private String metadataFieldName;
@Value("${langchain4j-demo.milvus.vectorFieldName}")
private String vectorFieldName;
@Bean
public EmbeddingStore embeddingStore() {
MilvusEmbeddingStore store = MilvusEmbeddingStore.builder()
.host(host)
.port(port)
.databaseName(databaseName)
.collectionName(collectionName)
.dimension(1536)
.indexType(IndexType.IVF_FLAT)
.metricType(MetricType.COSINE)
.consistencyLevel(ConsistencyLevelEnum.BOUNDED)
.autoFlushOnInsert(true)
.idFieldName(idFieldName)
.textFieldName(textFieldName)
.metadataFieldName(metadataFieldName)
.vectorFieldName(vectorFieldName)
.build();
return store;
}
}
|
将向量模型的bean注册到Spring
添加配置
在application.properties中添加需要的配置项(向量模型的安装使用查看文章打造私有知识库)
1
2
3
4
| bailian.api-key=sk-xxx
bailian.modelName=text-embedding-v1
bailian.baseUrl=https://dashscope.aliyuncs.com/compatible-mode/v1
bailian.dimensions=1536
|
添加代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| @Configuration
public class EmbeddingModelConfig {
@Value("${bailian.api-key}")
private String bianlianApiKey;
@Value("${bailian.modelName}")
private String bailianModelName;
@Value("${bailian.baseUrl}")
private String bailianBaseUrl;
@Value("${bailian.dimensions}")
private int bailianDimensions;
@Primary
@Bean
public EmbeddingModel bailianEmbeddingModel() {
OpenAiEmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey(bianlianApiKey)
.modelName(bailianModelName)
.baseUrl(bailianBaseUrl)
.logRequests(true)
.logResponses(true)
.dimensions(bailianDimensions)
.timeout(Duration.ofMillis(3600))
.build();
return embeddingModel;
}
}
|
添加读取文件的工具类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| @Getter
@ToString
@AllArgsConstructor
public enum CrowdHeaderEnum {
ID(0, "id"),
TITLE(1, "title"),
OVERVIEW(2, "overview"),
RELEASE_DATE(3, "release_date");
int index;
String name;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| @Slf4j
public class ReadFileUtil {
public static List<Document> getCsvRowList(String path) {
List<Document> result = new ArrayList<>();
try {
CsvData data = CsvUtil.getReader().read(FileUtil.file(path));
if (Objects.isNull(data) || Objects.isNull(data.getRow(0)) || Objects.isNull(data.getRow(1))) {
log.error("read csv file empty!,path:{}", path);
}
for (int i = 1; i < data.getRowCount(); i++) {
CsvRow row = data.getRow(i);
String title = row.get(CrowdHeaderEnum.TITLE.getIndex());
String overview = row.get(CrowdHeaderEnum.OVERVIEW.getIndex());
Map<String, String> map = Map.of(CrowdHeaderEnum.ID.getName(), row.get(CrowdHeaderEnum.ID.getIndex()),
CrowdHeaderEnum.RELEASE_DATE.getName(), row.get(CrowdHeaderEnum.RELEASE_DATE.getIndex()));
Metadata metadata = Metadata.from(map);
Document document = new DefaultDocument(title + "," + overview, metadata);
result.add(document);
}
} catch (Exception e) {
log.error("ReadFileUtils#getCsvRowList fail!{}", Throwables.getStackTraceAsString(e));
}
return result;
}
}
|
添加数据初始化的接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
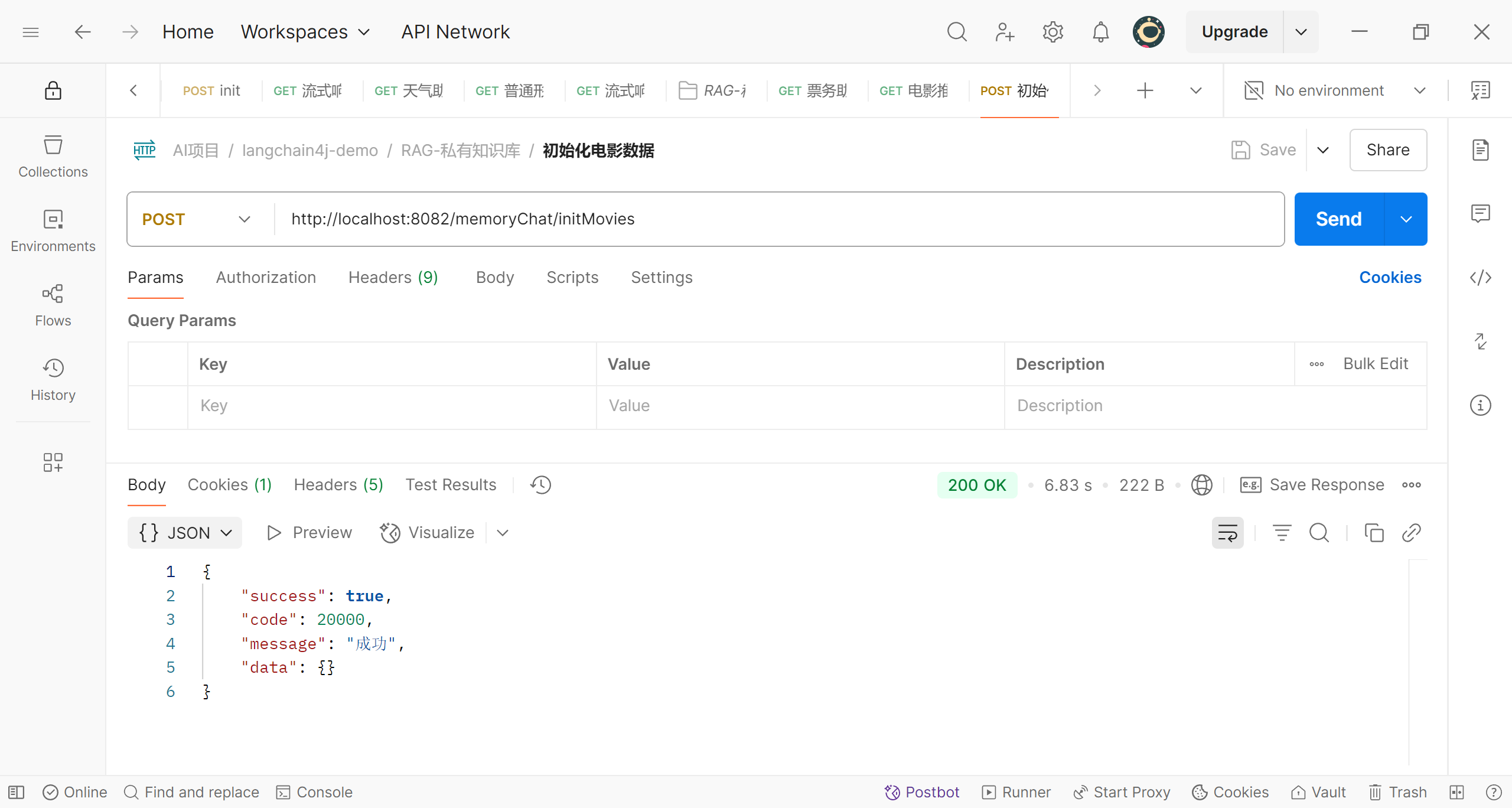
@PostMapping("/initMovies")
public Result initMoviesInfo() {
List<Document> csvRowList = ReadFileUtil.getCsvRowList(filePaht);
List<String> ids = new ArrayList<>();
List<Embedding> embeddingList = new ArrayList<>();
List<TextSegment> textSegments = new ArrayList<>();
for (Document document : csvRowList) {
Response<Embedding> response = bailianEmbeddingModel.embed(document.text());
Embedding embedding = response.content();
embeddingList.add(embedding);
Metadata metadata = document.metadata();
Map<String, Object> map = metadata.toMap();
String id = map.get(CrowdHeaderEnum.ID.getName()).toString();
ids.add(id);
TextSegment textSegment = new TextSegment(document.text(), metadata);
textSegments.add(textSegment);
}
embeddingStore.addAll(ids, embeddingList, textSegments);
return Result.ok();
}
|
我们可以调用该接口将csv文件中的数据初始化到Milvus向量数据库;我们可以用postman测试一下
我们来看看Milvus数据库中的情况(我已经将之前的数据清空了)
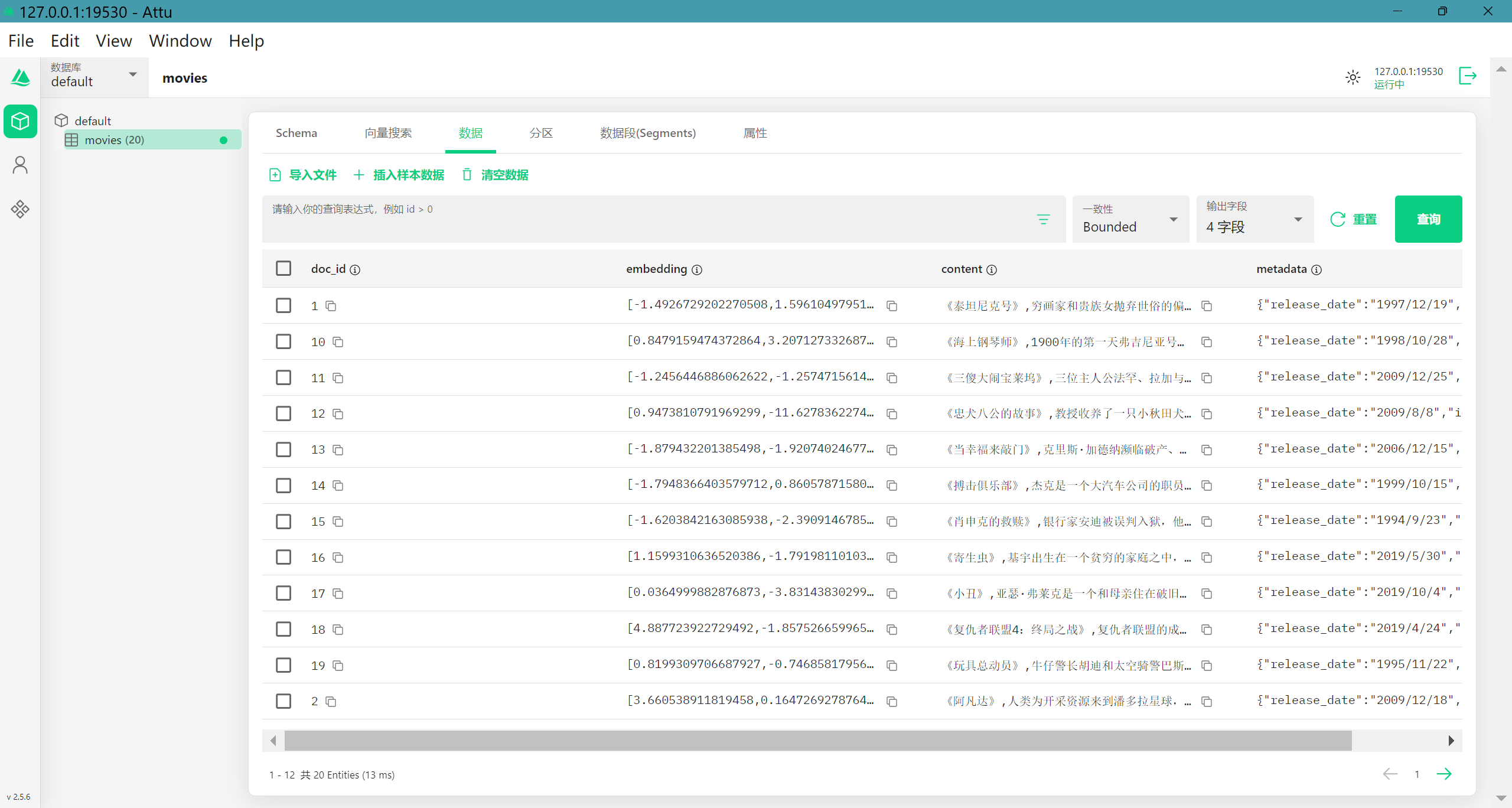
可以看到数据已经成功初始化了
添加推荐电影的智能助手
我们还是先添加一个接口
1
2
3
4
5
6
7
8
9
10
11
12
13
| public interface RagAssistant {
@SystemMessage("""
你是我(qiuli)的私人知识库管理员,请你友好、礼貌的回答关于电影推荐的问题。
""")
TokenStream chatForMovies(@MemoryId int memoryId, @UserMessage String message);
}
|
再添加具体实现,可以看到,与之前实现的智能助手相比,我们在初始化AI服务时添加一个增强检索流程的组件,即defaultRetrievalAugmentor对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| @Configuration
public class RagAssistantConfig {
@Resource
private PersistentChatMemoryStore persistentChatMemoryStore;
@Resource
private EmbeddingStore embeddingStore;
@Autowired
@Qualifier("bailianEmbeddingModel")
private EmbeddingModel bailianEmbeddingModel;
@Autowired
@Qualifier("deepSeekChatModel")
private OpenAiChatModel deepSeekChatModel;
@Autowired
@Qualifier("deepseekStreamingChatModel")
private OpenAiStreamingChatModel deepseekStreamingChatModel;
@Bean
public RagAssistant movieRecommendFunctionAssistant() {
ChatMemoryProvider chatMemoryProvider = memoryId -> {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(persistentChatMemoryStore)
.build();
};
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(bailianEmbeddingModel)
.embeddingStore(embeddingStore)
.maxResults(10)
.minScore(0.5)
.build();
QueryTransformer queryTransformer = new CompressingQueryTransformer(deepSeekChatModel);
DefaultRetrievalAugmentor defaultRetrievalAugmentor = DefaultRetrievalAugmentor.builder()
.queryTransformer(queryTransformer)
.contentRetriever(contentRetriever)
.build();
RagAssistant movieRecommendFunctionAssistant = AiServices.builder(RagAssistant.class)
.chatMemoryProvider(chatMemoryProvider)
.retrievalAugmentor(defaultRetrievalAugmentor)
.chatLanguageModel(deepSeekChatModel)
.streamingChatLanguageModel(deepseekStreamingChatModel)
.build();
return movieRecommendFunctionAssistant;
}
}
|
添加推荐电影的API接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
@GetMapping(value = "/getMovies", produces = "text/stream;charset=UTF-8")
public Flux<String> getMovies(@RequestParam int chatId,
@RequestParam(value = "message", defaultValue = "hello") String message) {
TokenStream tokenStream = movieRecommendFunctionAssistant.chatForMovies(chatId, message);
Flux<String> flux = Flux.create(fluxSink -> {
tokenStream
.onPartialResponse(s -> fluxSink.next(s))
.onCompleteResponse(chatResponse -> fluxSink.complete())
.onError(throwable -> log.error(throwable.getMessage(), throwable))
.start();
});
return flux;
}
|
好了,现在我们可以进行测试了,让程序为我们推荐一部爱情电影

再来一部动作电影
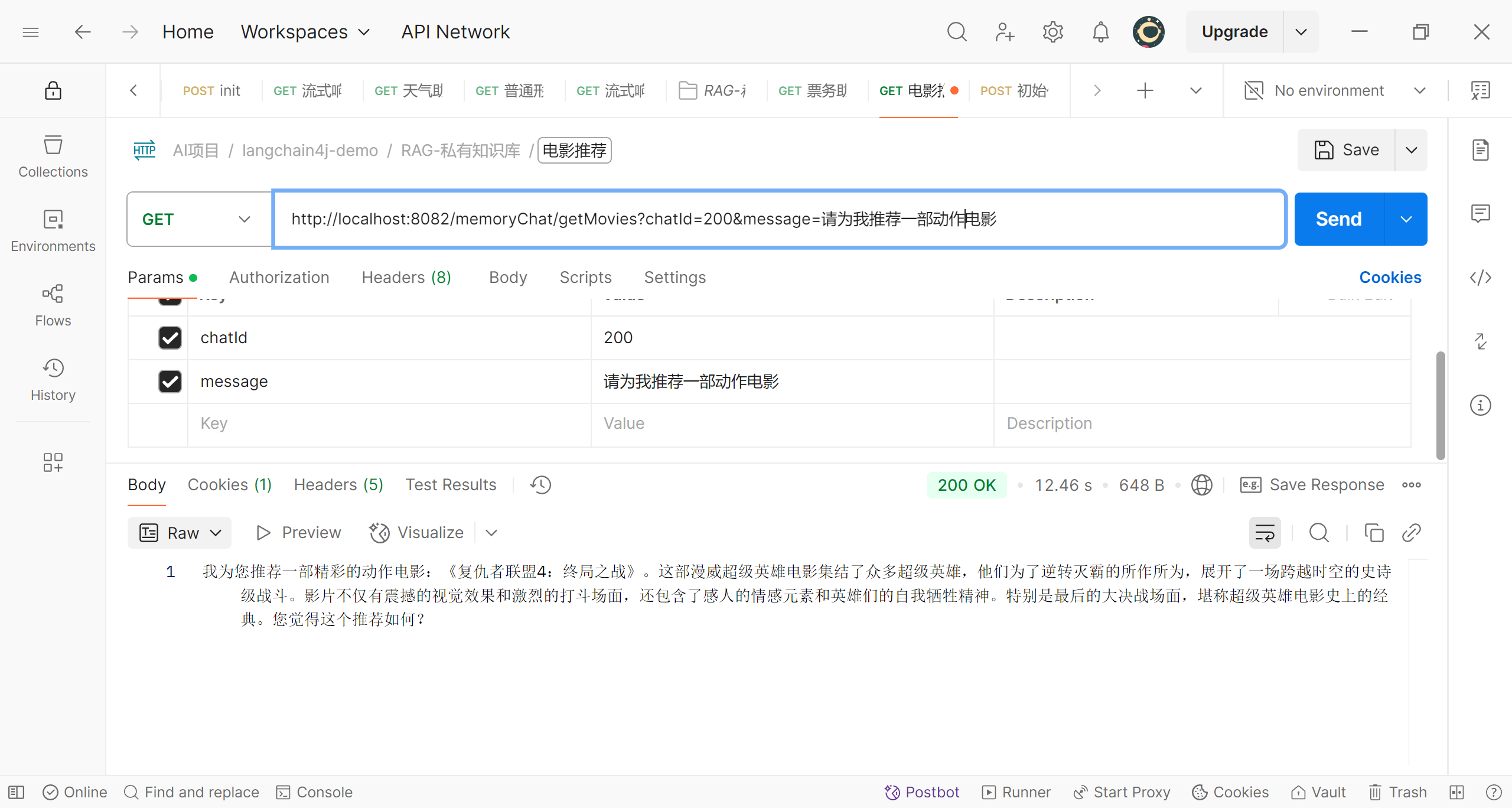
这样,我们的后端代码就完成了
前端代码实现
我们使用字节的Trae来简单的写一个前端页面,使用vue框架;我不得不说现在ai已经越来越牛了,写这些简单的页面已经没有什么压力了;这里我也不再赘述,要注意的是为了让浏览器能自动解析数据,格式使用‘text/event-stream’,要将后端的返回格式也修改为该格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
@GetMapping(value = "/getMovies", produces = "text/event-stream;charset=UTF-8")
public Flux<String> getMovies(@RequestParam int chatId,
@RequestParam(value = "message", defaultValue = "hello") String message) {
TokenStream tokenStream = movieRecommendFunctionAssistant.chatForMovies(chatId, message);
Flux<String> flux = Flux.create(fluxSink -> {
tokenStream
.onPartialResponse(s -> fluxSink.next(s))
.onCompleteResponse(chatResponse -> fluxSink.complete())
.onError(throwable -> log.error(throwable.getMessage(), throwable))
.start();
});
return flux;
}
|
部分前端代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
| <template>
<div class="chat-container">
<h1>电影推荐助手</h1>
<div class="chat-box">
<div v-for="(msg, index) in messages" :key="index" :class="msg.type">
{{ msg.text }}
</div>
</div>
<div class="input-area">
<input
v-model="userInput"
placeholder="请输入你的请求,例如:推荐一部动作电影"
@keyup.enter="sendMessage"
/>
<button @click="sendMessage">发送</button>
</div>
</div>
</template>
<script>
export default {
data() {
return {
userInput: '',
messages: [
{
type: 'assistant',
text: '你好!我是电影推荐助手,可以为你推荐各种类型的电影。'
}
],
// chatId: Date.now()
chatId: 100,
// 用于取消请求
abortController: null
};
},
methods: {
async sendMessage() {
const input = this.userInput.trim();
if (!input) return;
// 取消之前的请求(如果有)
if (this.abortController) {
this.abortController.abort();
}
this.abortController = new AbortController();
this.messages.push({
type: 'user',
text: input
});
this.userInput = '';
// 添加"正在生成"的提示消息
this.messages.push({
type: 'assistant',
text: '正在为您生成推荐...'
});
// 正确定义responseIndex
const responseIndex = this.messages.length - 1;
try {
const response = await fetch(
`http://localhost:8082/memoryChat/getMovies?chatId=${this.chatId}&message=${encodeURIComponent(input)}`,
{
headers: {
'Accept': 'text/event-stream'
},
// 添加取消支持
signal: this.abortController.signal
}
);
console.log('请求状态:', response.status);
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
let fullResponse = '';
// 清空初始提示(可选)
this.messages[responseIndex].text = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 处理可能的SSE格式
const chunk = decoder.decode(value)
const lines = chunk.split('\n');
let processedResponse = '';
lines.forEach(line => {
if (line.startsWith('data:')) {
processedResponse += line.substring(5).trim() + ' ';
}
});
fullResponse += processedResponse;
// 实时更新消息内容
this.messages[responseIndex].text = fullResponse;
// 自动滚动到底部
this.$nextTick(() => {
const chatBox = this.$el.querySelector('.chat-box');
chatBox.scrollTop = chatBox.scrollHeight;
});
}
} catch (error) {
if (error.name !== 'AbortError') {
console.error('API调用失败:', error);
this.messages[responseIndex].type = 'error';
this.messages[responseIndex].text = '获取推荐失败,请稍后再试';
}
} finally {
this.abortController = null;
}
}
},
beforeUnmount() {
// 组件卸载时取消所有请求
if (this.abortController) {
this.abortController.abort();
}
}
};
</script>
<style scoped>
.chat-container {
max-width: 800px;
margin: 2rem auto; /* 保持居中 */
padding: 1rem;
font-family: Arial, sans-serif;
width: 100%;
}
.chat-box {
height: 500px;
border: 1px solid #e0e0e0;
border-radius: 8px;
margin: 1rem auto; /* 使用auto实现居中 */
padding: 1rem;
overflow-y: auto;
background-color: #f9f9f9;
width: 90%;
}
h1 {
text-align: center;
color: #2c3e50;
}
.user {
text-align: right;
margin: 0.5rem 0;
padding: 0.5rem 1rem;
background-color: #e3f2fd;
border-radius: 18px 18px 0 18px;
display: inline-block;
max-width: 70%;
margin-left: 30%;
}
.assistant {
text-align: left;
margin: 0.5rem 0;
padding: 0.5rem 1rem;
background-color: #f1f1f1;
border-radius: 18px 18px 18px 0;
display: inline-block;
max-width: 70%;
}
.error {
color: #d32f2f;
padding: 0.5rem;
text-align: center;
}
.input-area {
display: flex;
gap: 0.5rem;
}
input {
flex: 1;
padding: 0.75rem;
border: 1px solid #e0e0e0;
border-radius: 4px;
font-size: 1rem;
}
button {
padding: 0.75rem 1.5rem;
background-color: #1976d2;
color: white;
border: none;
border-radius: 4px;
cursor: pointer;
font-size: 1rem;
}
button:hover {
background-color: #1565c0;
}
</style>
|
最终的效果为:
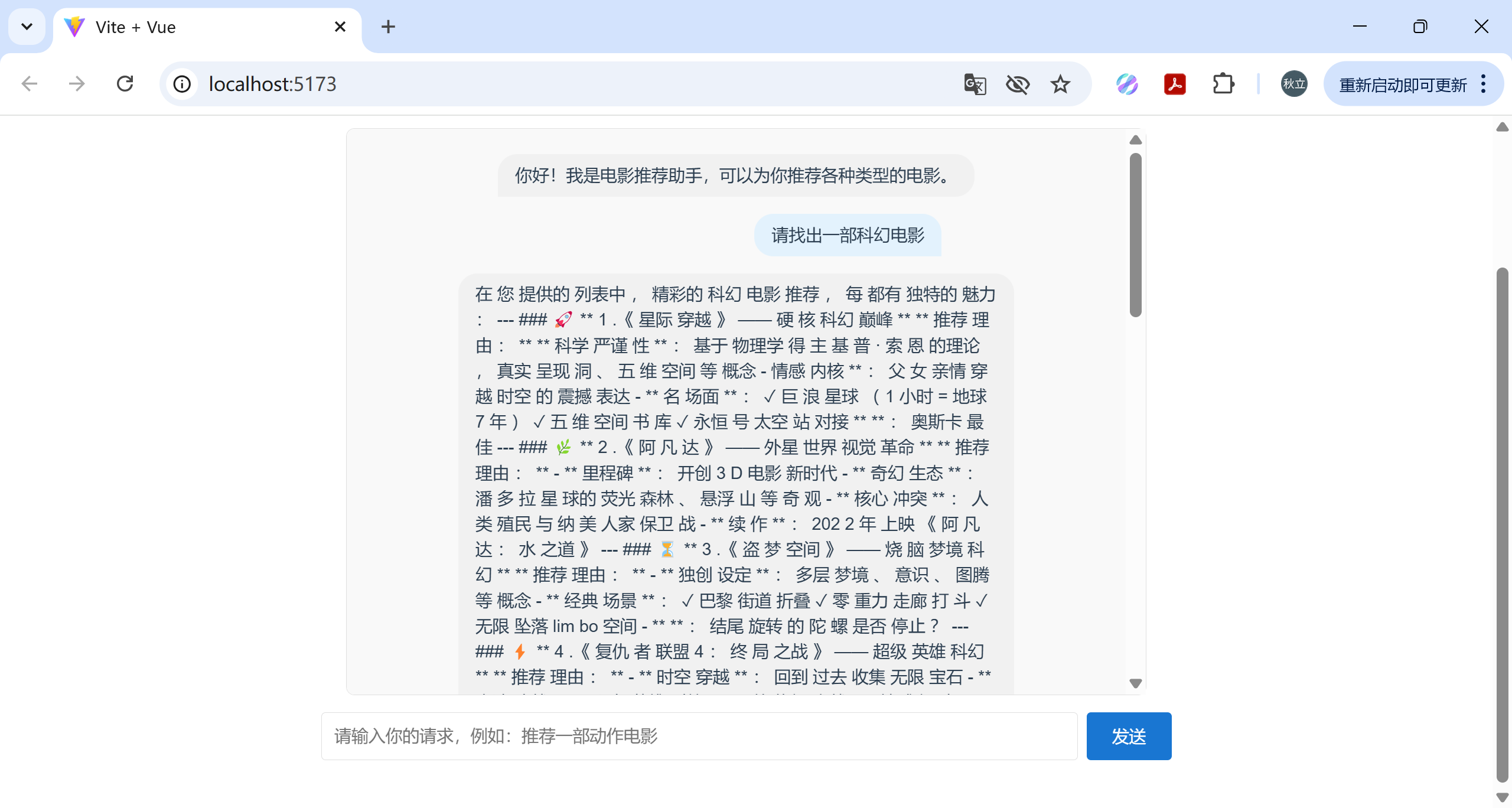
实现效果