前言 Kubernetes,简称K8s,是一个开源的容器编排平台,用于自动化应用程序的部署、扩展和管理。本文我们来搭建一个简单的kubernetes集群。
基本环境准备
(1)我们这次搭建的环境包括4个节点,1个master节点和3个worker节点,每台虚拟机的资源为:2core、4G内存、50G硬盘;虚拟机安装的镜像为:CentOS-7-x86_64-Minimal-2009.iso
(2)为虚拟机设置静态IP,我设置4台机器的ip为
1 2 3 4 192.168.218.131 192.168.218.132 192.168.218.133 192.168.218.134
(3)为虚拟机设置主机名,我设置4台机器的主机名为
1 2 3 4 192.168.218.131 k8s-master 192.168.218.132 k8s-worker1 192.168.218.133 k8s-worker2 192.168.218.134 k8s-worker3
(4)设置虚拟机的hosts,使虚拟机可以利用主机名互相访问
1 2 3 4 5 6 7 8 # 进入hosts文件 sudo vi /etc/hosts # 将ip和主机名对应关系添加到末尾 192.168.218.131 k8s-master 192.168.218.132 k8s-worker1 192.168.218.133 k8s-worker2 192.168.218.134 k8s-worker3
(5)关闭linux安全模块selinux
(6)关闭系统交换分区(swap area)
(7)关闭防火墙
(8)将桥接网络的IPv4流量转发到iptables
(9)设置三台虚拟机的时间同步并设置时区
镜像工具安装 1. 安装docker (1)参考‘虚拟机的初始准备’ -‘安装基础软件’-‘安装docker’,这里安装的版本是:20.10.24 (2)修改docker的cgroup 驱动 1 2 3 4 5 6 7 8 9 # 编辑文件‘/etc/docker/daemon.json’,添加如下内容 { "exec-opts" : [ "native.cgroupdriver=systemd" ] , "log-driver" : "json-file" , "log-opts" : { "max-size" : "100m" } , "storage-driver" : "overlay2" }
保存文件后,重启 Docker 服务以应用更改
1 2 sudo systemctl daemon-reload sudo systemctl restart docker
确认 Docker 已切换到 systemd
1 2 # 应该输出:Cgroup Driver: systemd docker info | grep -i cgroup
2. 安装kubeadm、kubelet、kubectl
Kubeadm 是一个快捷搭建kubernetes(k8s)的安装工具,它提供了 kubeadm init 以及 kubeadm join 这两个命令来快速创建 kubernetes 集群,kubeadm 通过执行必要的操作来启动和运行一个最小可用的集群
Kubelet 是 kubernetes 工作节点上的一个代理组件,运行在每个节点上
kubectl是Kubernetes集群的命令行工具,通过kubectl能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署
(1)修改yum的kubernetes镜像源 1 2 # 编辑该文件 vi /etc/yum.repos.d/kubernetes.repo
1 2 3 4 5 6 7 8 9 # 在文件中添加如下内容,我们这里使用阿里云的镜像源 [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-$basearch enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg exclude=kube*
1 2 3 # 清理并更新缓存 sudo yum clean all sudo yum makecache
(2)使用yum安装 1 2 3 # --disableexcludes=kubernetes 只能使用kubernetes仓库(我们上一步设置的仓库) sudo yum -y install kubelet-1.21.0-0 kubeadm-1.21.0-0 kubectl-1.21.0-0 \ --disableexcludes=kubernetes
(3)启动服务、设置开机自启、查看服务状态 1 2 3 4 # kubelet sudo systemctl status kubelet sudo systemctl start kubelet sudo systemctl enable kubelet
初始化kubernetes节点 1. 初始化master节点 (1)初始化 1 2 3 4 5 6 7 8 9 10 11 12 # 查看kubeadm有哪些版本可用 yum list --showduplicates kubeadm --disableexcludes=kubernetes # 初始化 # --image-repository registry.aliyuncs.com/google_containers:使用阿里云镜像源 # --kubernetes-version=v1.21.0:指定k8s的版本 # --pod-network-cidr=192.168.254.0/24: 指定pod的网段 # 我们第一次使用这个命令不会初始化成功,因为阿里云镜像源中缺乏一个coredns镜像 kubeadm init \ --image-repository registry.aliyuncs.com/google_containers \ --kubernetes-version=v1.21.0 \ --pod-network-cidr=192.168.254.0/24
- 注:pod的概念类似docker-compose中的一个docker-compose.yml文件所管理的容器;一个docker-compose.yml文件启动的容器会共享一些资源,如网络、存储卷、环境变量等;这里的网段为什么是‘192.168.254.0/24’,因为calico默认的网段是‘192.168.0.0’
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 如果初始化成功,我们会看到这样一段信息: Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.218.131:6443 --token 3679yv.0vxbxqragunypp8y \ --discovery-token-ca-cert-hash sha256:0ec8eafa7ecdcb439e503ea2a07c67b4479774b1c7a6c86423710e230fcc5c67
我们可以根据提示信息创建目录和配置文件
1 2 3 4 5 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
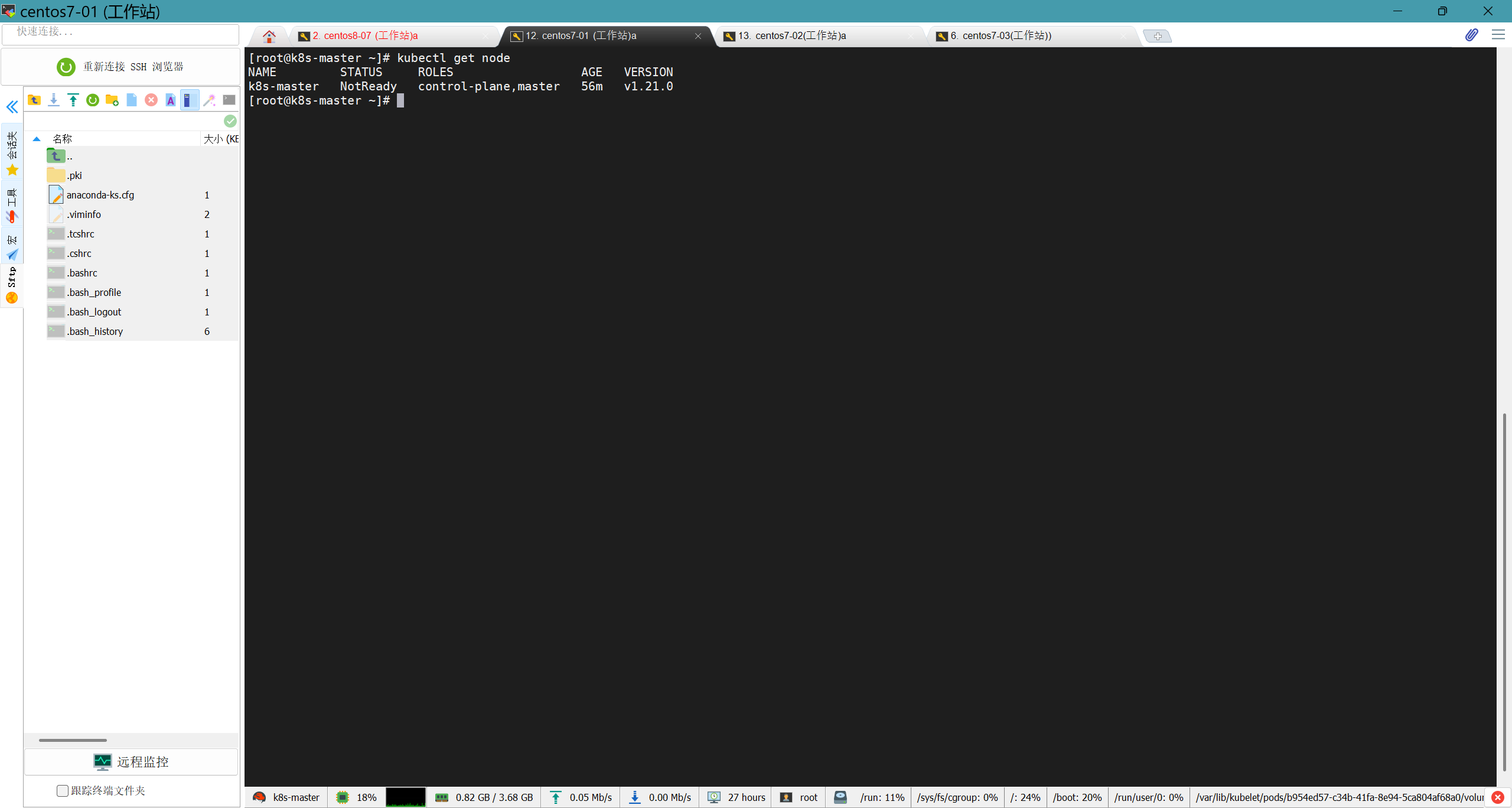
使用如下命令查看节点
如果之前的操作都没问题,我们已经可以看到master节点了
(2)可能出现的问题 a. 阿里云镜像源中没有coredns镜像
1 2 3 4 5 6 7 # 手动拉取coredns镜像 docker pull coredns/coredns:v1.8.0 # 将这个镜像重命名,否则k8s无法识别 docker tag coredns/coredns:1.8.0 registry.aliyuncs.com/google_containers/coredns/coredns:v1.8.0 # 查看是否重命名成功 docker images # (看到'registry.aliyuncs.com/google_containers/coredns/coredns v1.8.0' )
b. 报错信息:WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at https://kubernetes.io/docs/setup/cri/;这是需要修改docker的cgroup 驱动
2. 添加worker节点 上一条目中初始化master成功,输出的命令中有信息
1 2 3 4 Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.218.131:6443 --token 3679yv.0vxbxqragunypp8y \ --discovery-token-ca-cert-hash sha256:0ec8eafa7ecdcb439e503ea2a07c67b4479774b1c7a6c86423710e230fcc5c67
我们可以根据该命令将worker节点添加到集群中,但是需要保证worker节点虚拟机已经正确安装了docker、kubelet、kubectl,并且这些服务已经正确启动;
1 2 sudo systemctl status docker sudo systemctl status kubelet
worker节点添加成功会显示如下信息
1 2 3 4 5 This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
根据提示信息,在master节点使用如下命令来查看添加的worker节点
1 2 # 不做配置,这个命令默认在master节点生效 kubectl get nodes
如果忘记了添加worker节点的命令,可以在master节点用如下命令获取
1 kubeadm token create --print-join-command
部署CNI网络插件calico 虽然现在k8s集群已经有1个master节点,2个worker节点,但是此时三个节点的状态都是NotReady的,原因是没有CNI网络插件 ,为了节点间的通信,需要安装cni网络插件,常用的cni网络插件有calico和flannel,两者区别为:flannel不支持复杂的网络策略,calico支持网络策略,因为今后还要配置k8s网络策略networkpolicy,所以本文选用的cni网络插件为calico
1.去官网下载calico.yaml文件 官网:https://projectcalico.docs.tigera.io/about/about-calico
搜索框里搜索calico.yaml,找到下载链接
1 2 # 下载链接 curl https://raw.githubusercontent.com/projectcalico/calico/v3.29.2/manifests/calico.yaml -O
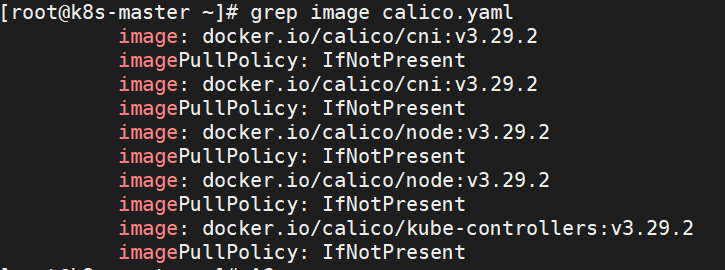
2.下载镜像 下载后我们可以看看calico.yaml文件中有哪些需要下载的镜像,使用命令‘grep image calico.yaml’
calico.yaml中过滤出的镜像名称
1 2 3 4 5 6 7 8 9 # 排除重复和无效内容,还有如下三个镜像 image: docker.io/calico/cni:v3.29.2 image: docker.io/calico/node:v3.29.2 image: docker.io/calico/kube-controllers:v3.29.2 # 手动拉取 docker pull docker.io/calico/cni:v3.29.2 docker pull docker.io/calico/node:v3.29.2 docker pull docker.io/calico/kube-controllers:v3.29.2
3.修改calico.yaml文件中的配置信息 修改calico.yaml文件中的CALICO_IPV4POOL_CIDR项,将其修改为初始化master节点时设置的pod网段
1 2 3 - name: CALICO_IPV4POOL_CIDR value: "192.168.254.0/24"
使用命令查看calico.yaml是否正确修改了
1 cat calico.yaml | egrep "CALICO_IPV4POOL_CIDR|"192.168""
calico.yaml文件中被修改的内容
使用kubectl加载calico.yaml
1 kubectl apply -f calico.yaml
我们再使用命令查看节点状态,可以看到节点状态现在变成‘ready’了
可以看到所有节点的状态都已经为‘Ready’
kubernetes的相关概念 namespace(命名空间)
作用 :Namespace 是 Kubernetes 中用于资源隔离的逻辑分区。它可以将集群资源划分为多个虚拟集群,每个 Namespace 中的资源名称可以重复,但在不同 Namespace 之间是隔离的。使用场景 :
将不同团队或项目的资源隔离开。
管理不同环境(如开发、测试、生产)的资源。
示例 :
1 2 3 4 apiVersion: v1 kind: Namespace metadata: name: my-namespace
ConfigMap(配置映射)
1 2 3 4 5 6 7 8 apiVersion: v1 kind: ConfigMap metadata: name: my-config data: app.properties: | key1=value1 key2=value2
Service(服务,定义访问策略)
作用 :Service 用于定义一组 Pod 的访问策略,提供稳定的网络端点(IP 和端口),使外部或其他服务可以访问这些 Pod。使用场景 :
暴露应用程序给集群内部或外部访问。
负载均衡多个 Pod 的流量。
类型:
ClusterIP :默认类型,仅在集群内部访问。NodePort :通过节点 IP 和端口暴露服务。LoadBalancer :通过云提供商的负载均衡器暴露服务。
示例 :
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: v1 kind: Service metadata: name: my-service spec: selector: app: my-app ports: - protocol: TCP port: 80 targetPort: 8080 type: ClusterIP
StatefulSet(有状态应用集,部署有状态服务)
作用 :StatefulSet 用于管理有状态应用程序(如数据库、消息队列),确保 Pod 具有唯一的网络标识和持久化存储。特点 :
Pod 按顺序创建和删除。
每个 Pod 有唯一的名称和稳定的网络标识(如 pod-0, pod-1)。
支持持久化存储(PersistentVolume)。
使用场景 :
运行需要稳定网络标识和存储的应用,如 MySQL、Kafka 等。
示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 apiVersion: apps/v1 kind: StatefulSet metadata: name: my-statefulset spec: serviceName: "my-service" replicas: 3 selector: matchLabels: app: my-app template: metadata: labels: app: my-app spec: containers: - name: my-container image: my-image
Deployment(部署无状态服务)
作用 :Deployment 用于管理无状态应用程序,支持滚动更新、回滚和 Pod 的自动扩缩容。特点 :
定义 Pod 的副本数和更新策略。
支持声明式更新(通过修改 YAML 文件)。
自动管理 ReplicaSet,确保 Pod 数量符合预期。
使用场景 :
示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiVersion: apps/v1 kind: Deployment metadata: name: my-deployment spec: replicas: 3 selector: matchLabels: app: my-app template: metadata: labels: app: my-app spec: containers: - name: my-container image: my-image
PersistentVolume (PV)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv namespace: my-namespace spec: capacity: storage: 20Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain nfs: server: 10.198 .1 .155 path: "/data/nfs"
PersistentVolumeClaim (PVC)
定义 :PersistentVolumeClaim (PVC) 是用户对存储资源的请求。它类似于 Pod 对 CPU 和内存的请求,用户通过 PVC 申请特定大小和访问模式的存储资源。特点
动态绑定 :PVC 会自动绑定到符合条件的 PV。解耦存储和 Pod :Pod 通过 PVC 使用存储,而无需关心具体的 PV 实现。资源请求 :可以指定存储大小和访问模式。生命周期 :PVC 的生命周期通常与 Pod 绑定,但可以独立于 Pod 存在。
示例
1 2 3 4 5 6 7 8 9 10 11 apiVersion: v1 kind: PersistentVolumeClaim metadata: name: nfs-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi storageClassName: nfs
kubectl的一些常用操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 # 使用yaml文件创建资源 kubectl apply -f <filename.yaml> # 查看所有namespace kubectl get namespace # 创建一个namespace kubectl create namespace <namespace> # 查看某个namespace的详细信息 kubectl describe namespace <namespace> # 删除某个namespace kubectl delete namespace <namespace> # 查看configmap kubectl get configmap -n <namespace> # 查看Deployment kubectl get deployment -n <namespace> # 停止 Deployment (将容器数量缩减至0) kubectl scale deployment <deployment-name> --replicas=0 -n <namespace> # 删除 Deployment kubectl delete deployment <deployment-name> -n mysql # 查看statefulset kubectl get statefulset -n <namespace> # 停止statefulset (将容器数量缩减至0) kubectl scale statefulset <statefulset-name> --replicas=0 -n <namespace> # 查看Pod kubectl get pod -n <namespace> # 删除Pod kubectl delete pod <pod-name> -n <namespace> # 进入pod(mysql) kubectl exec -it <pod-name> -- mysql -uroot -ppassword # 查看pod日志 kubectl logs <pod-name> -n mysql -c <container-name> # 检查pod的控制器 kubectl get pod <pod-name> -n mysql -o yaml # 查看pv kubectl get pv # 删除pv kubectl delete pv <pv-name> # 查看pvc kubectl get pvc -n <namespace> # 删除pvc kubectl delete pvc <pvc-name> -n <namespace>